
TrWebOCR开源的离线OCR
什么是 OCR ?
OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。【百度百科】
什么是 Tr ?
TR(Text Recognition)是一款针对扫描文档的离线文本识别 SDK,核心代码全部采用 C++ 开发,并提供 Python 接口。
什么是 TrWebOCR ?
TrWebOCR 是基于开源项目 Tr(Text Recognition) 构建的开源、易用的中文离线 OCR,识别率媲美大厂,并且提供了易用的 web 页面及 web 的接口,方便日常工作使用或者其他程序来调用。
这是热心的网友推荐的,正好老苏整理小人书的时候用的着,有时候想从防拷贝的网页上抓些文字也是很方便的(当然你也可以安装 Simple Allow Copy 这样的 Chrome 插件)。
安装
在群晖上以 Docker 方式安装。
在注册表中搜索 TrWebOCR ,选择第一个 mmmz/trwebocr,版本选择 latest。

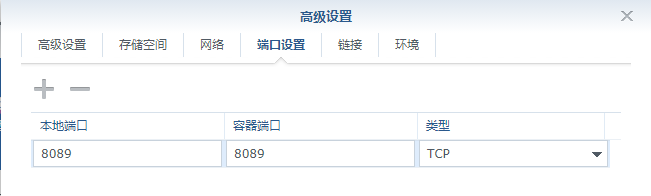
端口
端口不冲突就行
| 本地端口 | 容器端口 |
|---|---|
| 8089 | 8089 |
运行
在浏览器中输入 http://群晖IP:8089,就看到主界面
文字识别
打开小人书直接用截图工具框选要识别的部分

粘贴图片到网页中

点 识别 按钮

即便有些倾斜,但是识别率也是非常准确的
图文混排

粘贴图片到网页中

原始结果中正确的识别了文字,但是 识别的文字 中是空的

看来图片还是会对识别形成干扰
竖排文字

粘贴图片到网页中

有点混乱

基本上谈不上识别了,看来对于竖排文字有点无能为力
繁体中文
网上随便搜的一张名片

只有个别字识别存在错误,而且繁体识别出来的文字还是繁体
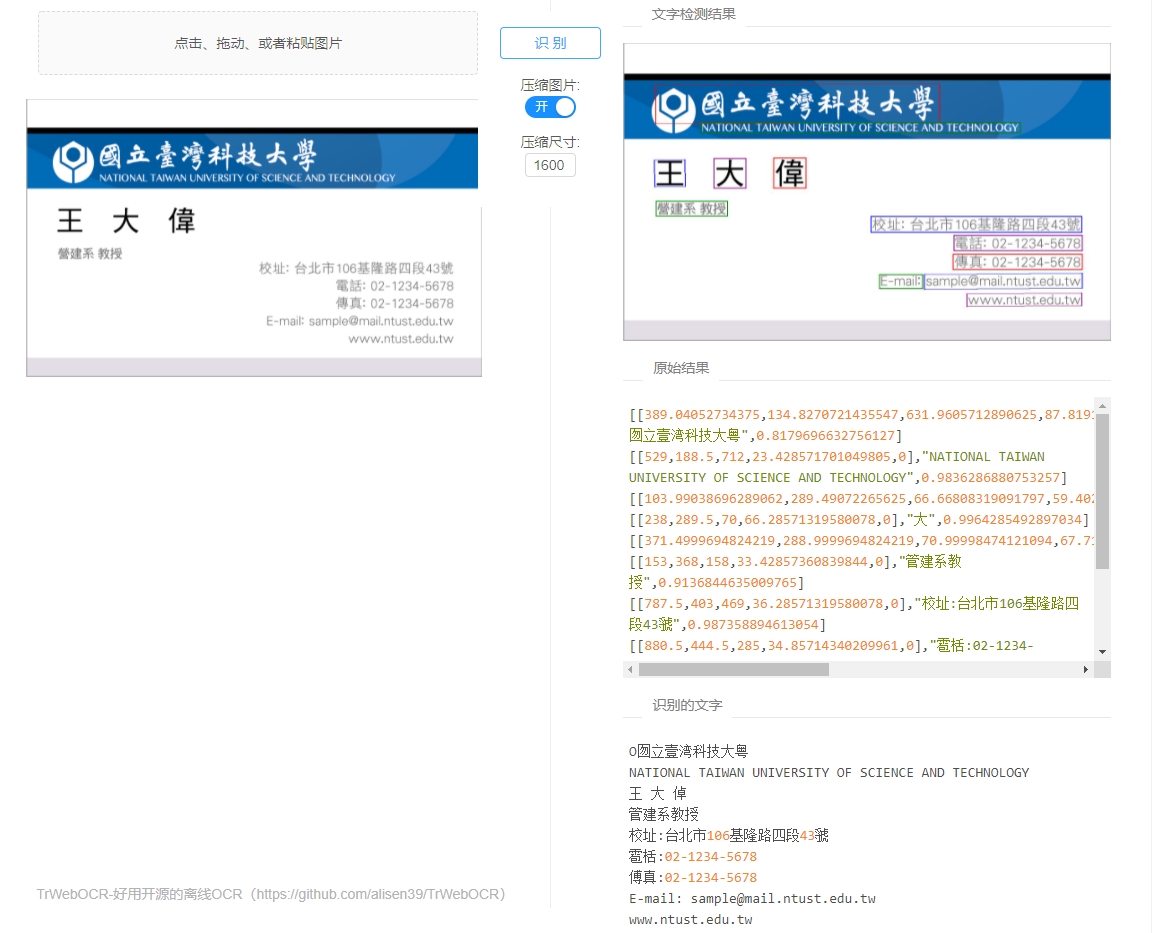
总体效果还是很不错的
小结
TrWebOCR 识别速度非常快,而且准确率很高,虽然代码已经一年没更新了,但对老苏来说绝对够用了
参考文档
alisen39/TrWebOCR: 开源易用的中文离线OCR,识别率媲美大厂,并且提供了易用的web页面及web的接口,方便人类日常工作使用或者其他程序来调用~
地址:https://github.com/alisen39/TrWebOCRmyhub/tr: Free Offline OCR 离线的中文文本检测+识别SDK
地址:https://github.com/myhub/tr