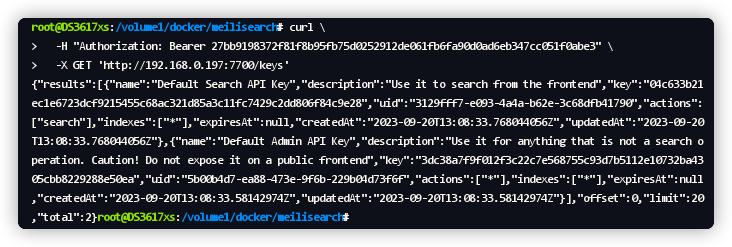
{ "results":[ { "name":"Default Search API Key", "description":"Use it to search from the frontend", "key":"04c633b21ec1e6723dcf9215455c68ac321d85a3c11fc7429c2dd806f84c9e28", "uid":"3129fff7-e093-4a4a-b62e-3c68dfb41790", "actions":[ "search" ], "indexes":[ "*" ], "expiresAt":null, "createdAt":"2023-09-20T13:08:33.768044056Z", "updatedAt":"2023-09-20T13:08:33.768044056Z" }, { "name":"Default Admin API Key", "description":"Use it for anything that is not a search operation. Caution! Do not expose it on a public frontend", "key":"3dc38a7f9f012f3c22c7e568755c93d7b5112e10732ba4305cbb8229288e50ea", "uid":"5b00b4d7-ea88-473e-9f6b-229b04d73f6f", "actions":[ "*" ], "indexes":[ "*" ], "expiresAt":null, "createdAt":"2023-09-20T13:08:33.58142974Z", "updatedAt":"2023-09-20T13:08:33.58142974Z" } ], "offset":0, "limit":20, "total":2 }
<body> <inputtype="search"id="search-bar-input"> <scriptsrc="https://cdn.jsdelivr.net/npm/docs-searchbar.js@latest/dist/cdn/docs-searchbar.min.js"></script> <script> docsSearchBar({ hostUrl: 'http://192.168.0.197:7700', apiKey: '04c633b21ec1e6723dcf9215455c68ac321d85a3c11fc7429c2dd806f84c9e28', indexUid: 'blog', inputSelector: '#search-bar-input', debug: true// Set debug to true if you want to inspect the dropdown }); </script> </body> </html>
hostUrl: 是 Meilisearch 的访问地址,如果远程访问的话可以反代成域名;
apiKey:用前面获取的 Default Search API Key;
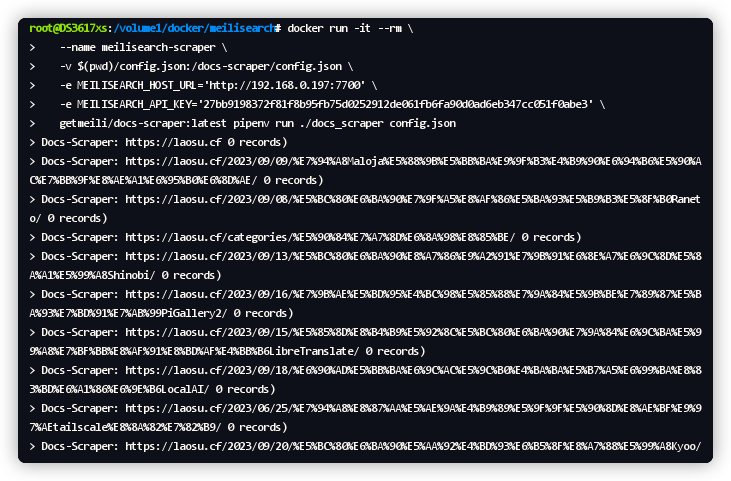
indexUid:就是在 config.json 中设置的 index_uid 的值;
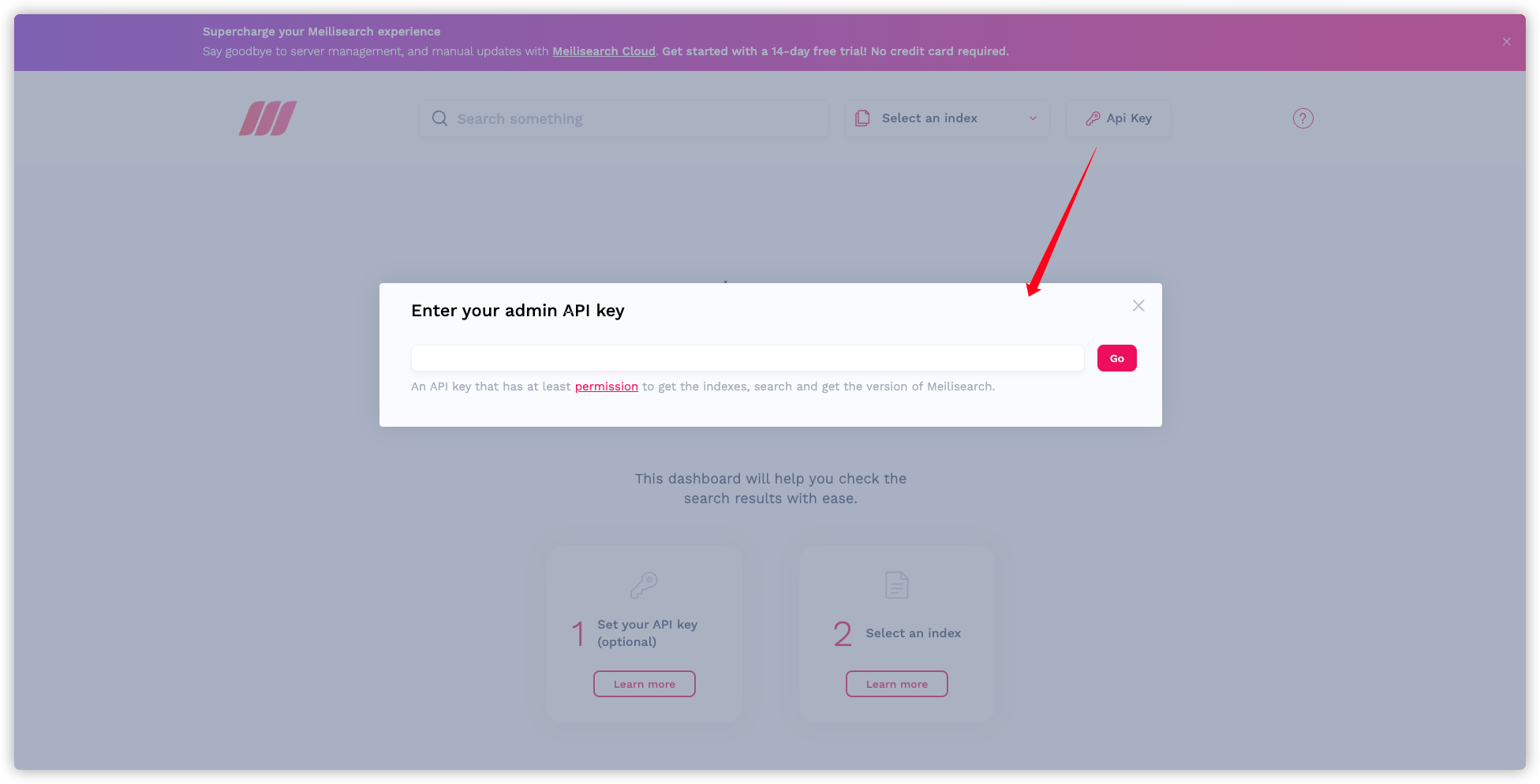
直接在浏览器中打开 search-bar.html 文件,只会在左上角看个一个文本框
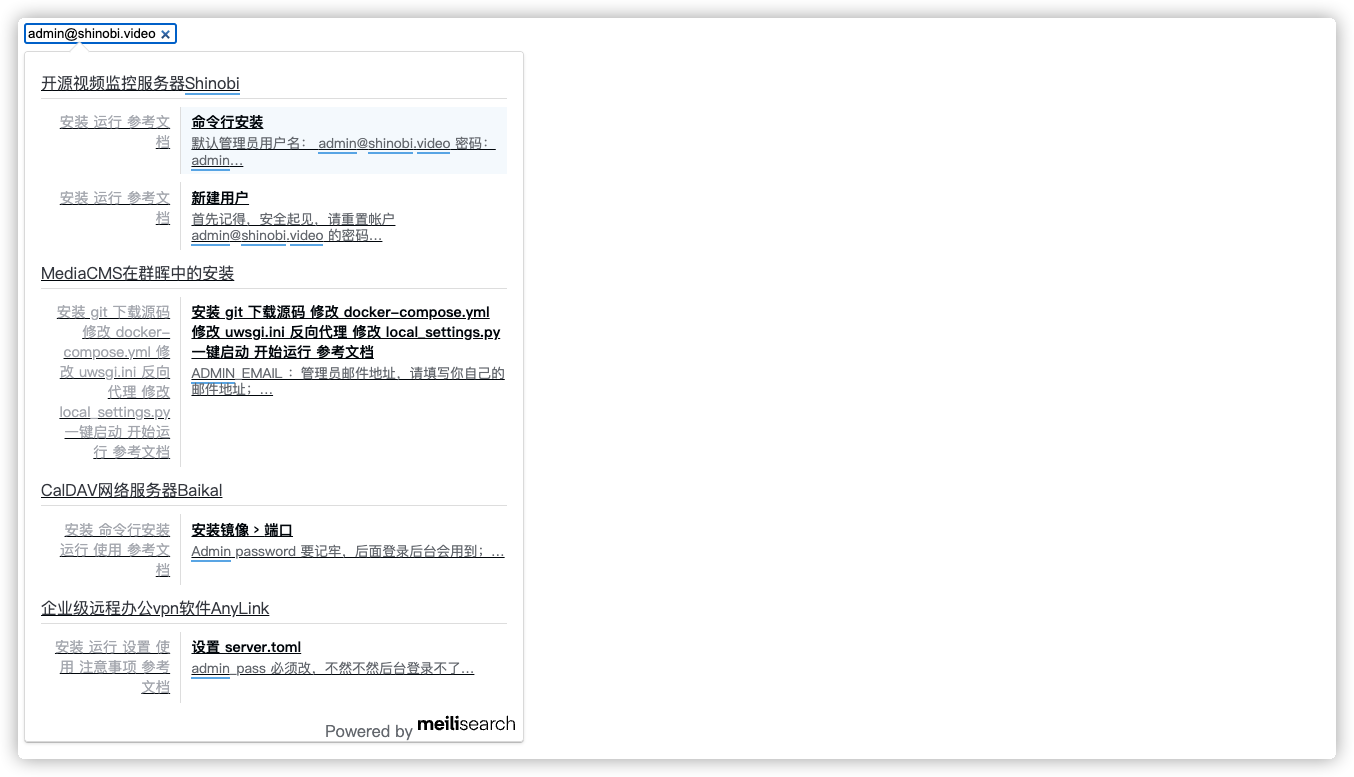
继续搜索 admin@shinobi.video
当然,如果你熟悉 html 的话,完全可以把上面这段 html 嵌入到你自己的页面中
参考文档
meilisearch/docs-scraper: Scrape documentation into Meilisearch 地址:https://github.com/meilisearch/docs-scraper