
OCRmyPDF让你能搜索扫描版PDF文档
什么是 OCRmyPDF ?
OCRmyPDF是一个Python应用程序和库,可以轻松地将图像处理和OCR(可识别、可搜索的文本)应用于现有OCR文本层,使你可以搜索或复制粘贴它们。

镜像下载
在群晖上以 Docker 方式安装。
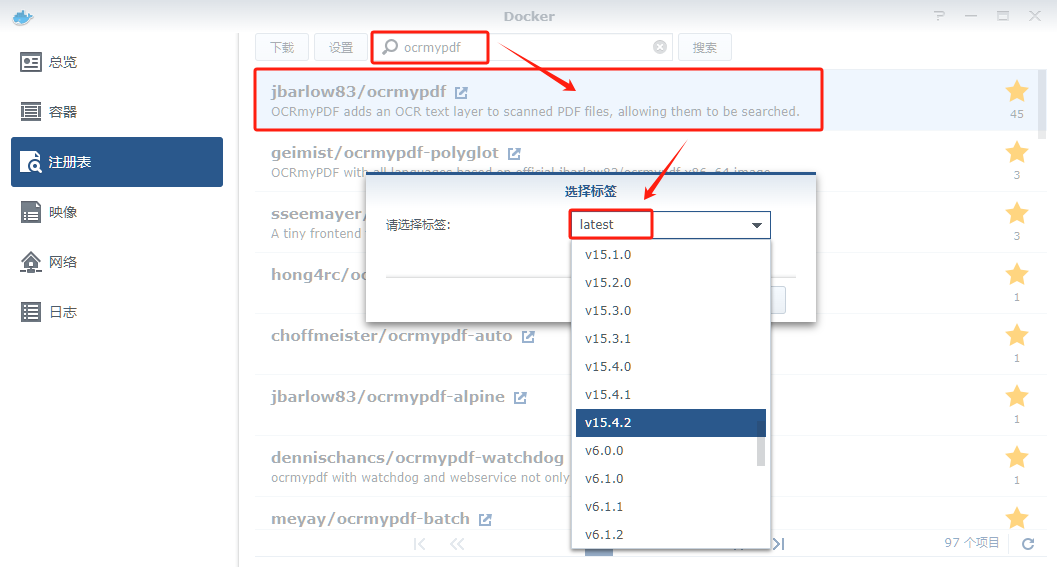
在注册表中搜索 ocrmypdf ,选择第一个 jbarlow83/ocrmypdf,版本选择 latest。
本文写作时,
latest版本对应为v15.4.2;
你也可以使用命令行,用 SSH 客户端登录到群晖后,依次执行下面的命令
1 | # 拉取镜像 |
如果拉不动,可以试试 docker 代理网站:https://dockerproxy.com/,但是会多几个步骤
1 | # 如果拉不动的话加个代理 |
下载完成后,可以在 映像 中找到

准备工作
【说明】:
- 与典型的
Docker容器不同,OCRmyPDF Docker容器是短暂的,它为一个OCR作业运行并终止,就像命令行程序一样。因此,我们通常使用--rm参数在容器退出时将其删除。- 默认情况下,
Docker镜像包括英语、德语、简体中文、法语、葡萄牙语和西班牙语,所以中文用户不需要添加语言包。
在 docker 文件夹中,创建一个新文件夹 ocrmypdf
1 | # 新建文件夹 ocrmypdf |
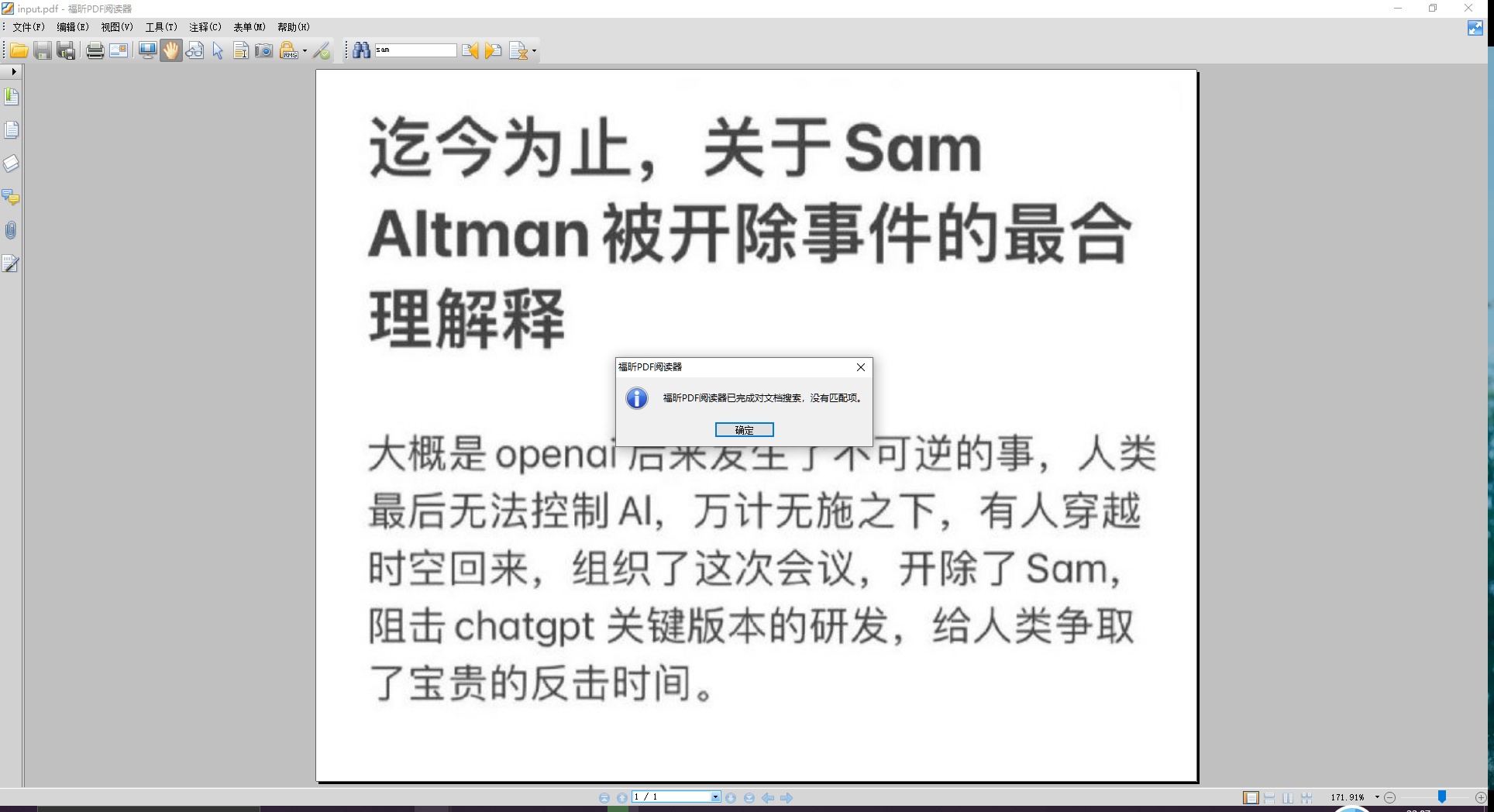
准备一个文档用于测试,这是网页上打印生成的 pdf 文件,直接搜索 sam 是没有 没有匹配项
将这个文档放入 ocrmypdf,命名为 input.pdf
测试验证
为了方便起见,创建一个 shell 别名来隐藏 Docker 命令。通过使用 alias 命令,为长或复杂的命令创建简短且易记的别名,以便更快地执行常用操作或减少输入的工作量
1 | # 创建别名 |
其中:
-- rm:表示在容器退出时,会将其删除;--user "$(id -u):$(id -g)":用于指定在容器内运行的用户和组,确保容器内的进程以与宿主机相同的用户权限运行,以防止权限问题;--workdir /data:指定容器内的工作目录;-v "$PWD:/data":将/volume1/docker/ocrmypdf映射到了容器内的/data;
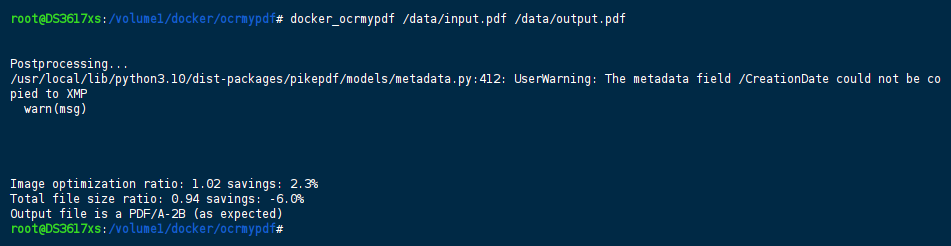
运行完成后,会在 ocrmypdf 中看到多出了一个文件 output.pdf
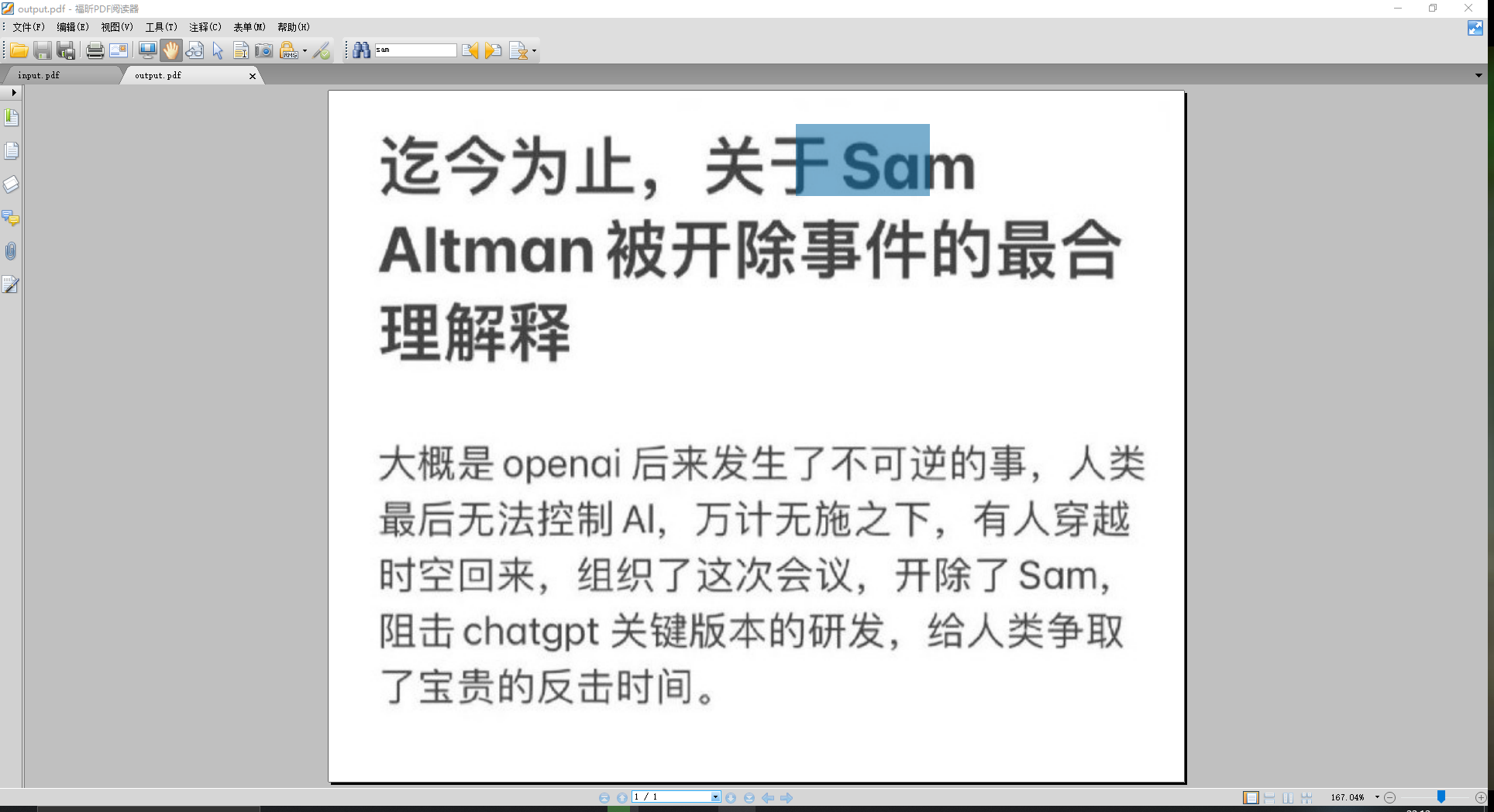
下载到本地后,用 pdf 阅读器打开后,继续搜索 sam 显示有 2 处匹配
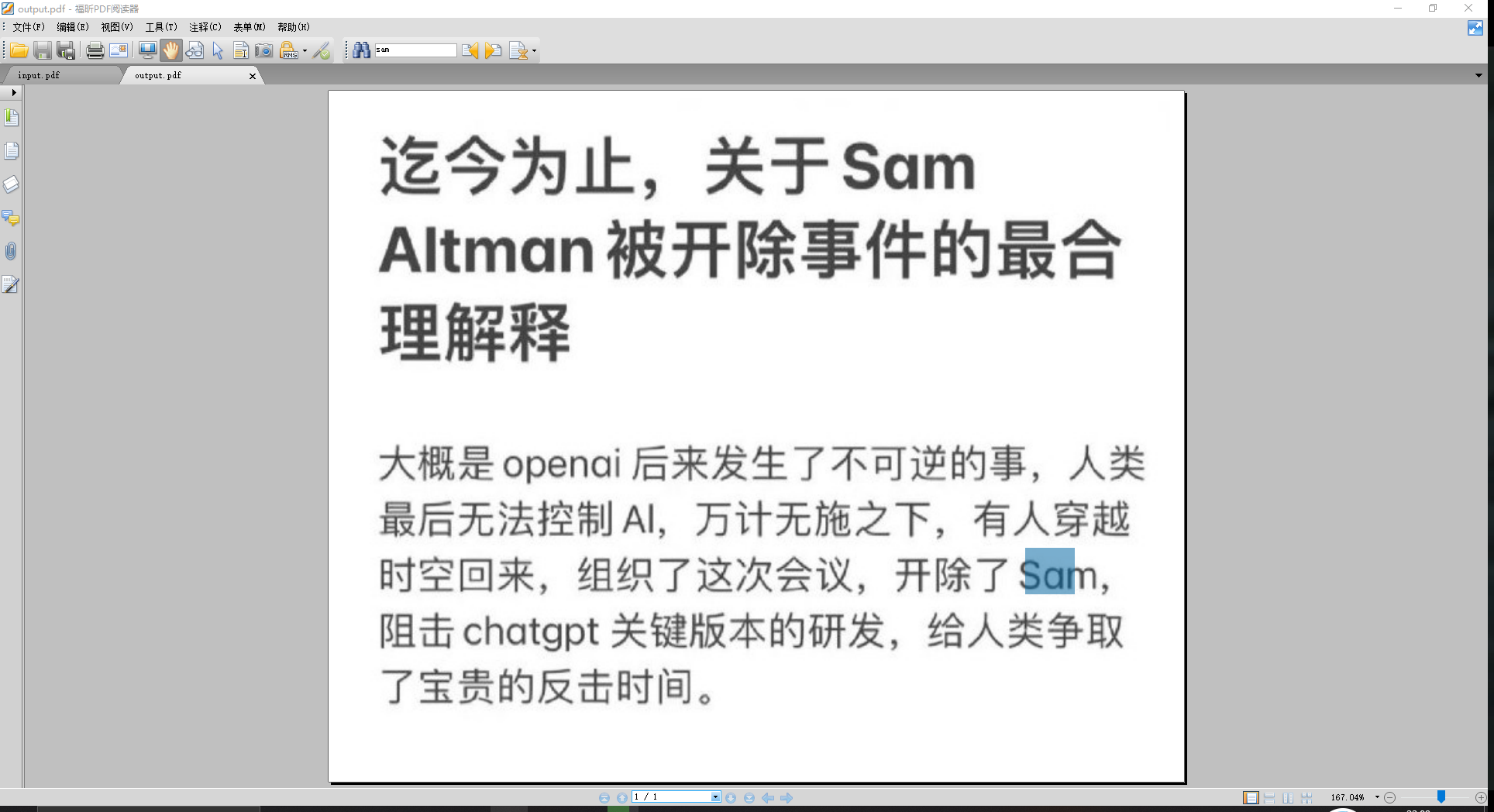
第二处
OCRmyPDF 不仅提供了基本的 OCR 功能,还包括一些高级功能,如自动旋转、自动裁剪、去除文本阴影、增强图像质量等。它使用了一些优秀的开源工具和库,如 Tesseract OCR 引擎、Ghostscript 和 ImageMagick,以提供强大的 OCR和 PDF处理功能,当然,OCRmyPDF 无法打开使用数字证书加密的文档。
参考文档
ocrmypdf/OCRmyPDF: OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
地址:https://github.com/ocrmypdf/OCRmyPDFOCRmyPDF documentation
地址:https://ocrmypdf.readthedocs.iojbarlow83/ocrmypdf - Docker Image | Docker Hub
地址:https://hub.docker.com/r/jbarlow83/ocrmypdf