
WebLLM Chat:无服务器、私密的AI聊天体验
简介
什么是 Web-LLM ?
Web-LLM是一个高性能的浏览器内语言模型推理引擎,允许用户在没有服务器支持的情况下直接在网页浏览器中进行语言模型推理。它利用WebGPU进行硬件加速,从而实现强大的LLM操作。Web-LLM完全兼容OpenAI API,支持流式处理、JSON模式生成以及自定义模型集成等功能,为开发者提供了构建AI助手和交互式应用的灵活性。通过简单的npm包,用户可以快速集成Web-LLM到他们的网页应用中。
主要特点包括:
- 浏览器内推理:用户可以直接在浏览器中运行大型语言模型,无需服务器支持。
- 隐私保护:所有数据处理均在本地进行,确保用户的对话和数据不离开设备。
- 兼容 OpenAI API:支持与
OpenAI API兼容的功能,如流式输出和JSON模式生成。 - 多模型支持:
WebLLM支持多种语言模型,用户可以根据需要选择和集成。 - 易于集成:开发者可以通过
npm包轻松将WebLLM集成到自己的应用中。
什么是 Web-LLM Chat ?
Web-LLM Chat是一个私有的AI聊天界面,结合了WebLLM的强大功能,允许用户在浏览器中本地运行大型语言模型(LLM)。它利用WebGPU加速,实现无须服务器支持的AI对话,确保用户的隐私和数据安全。该应用支持离线使用、图像上传和交互,提供友好的用户界面,具有Markdown支持和深色模式等功能。
构建镜像
如果你不想自己构建,可以跳过,直接阅读下一章节
官方提供了 Dockerfile,但没有提供编译好的镜像,需要自己编译
构建镜像和容器运行的基本命令如下👇
1 | # 下载代码 |
反向代理
如果使用 http 协议访问,页面上会有错误,导致页面卡死
1 | Failed to load resource: net::ERR_SSL_PROTOCOL_ERROR |

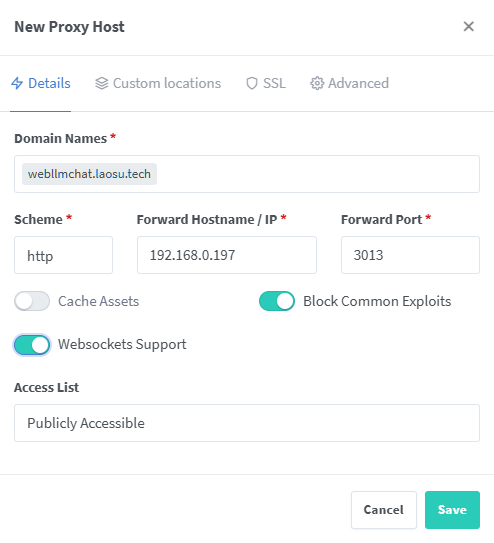
假设访问地址为: https://webllmchat.laosu.tech
| 域名 | 局域网地址 | 备注 |
|---|---|---|
webllmchat.laosu.tech |
http://192.168.0.197:3013 |
WebLLM Chat 的访问地址 |
如果你和老苏一样,没有具有公网 IP 的 vps,也是一样可以实现局域网用 https://域名 访问的
文章传送门:用自定义域名访问tailscale节点
在 npm 中的设置
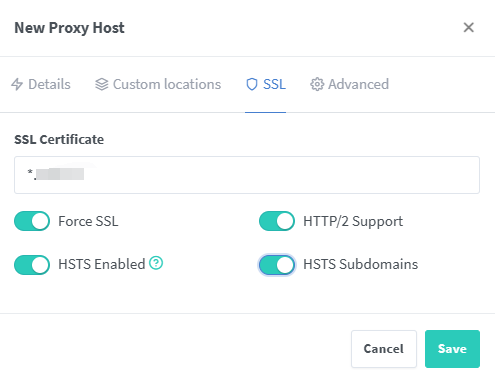
SSL 都勾选了
安装
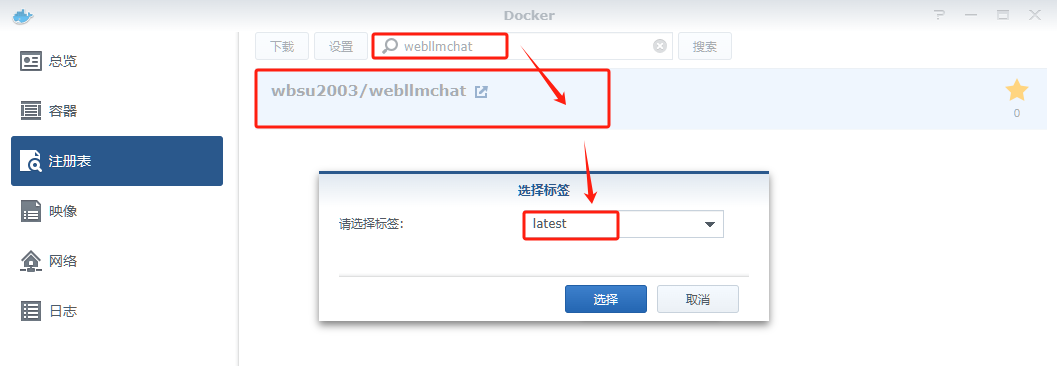
在群晖上以 Docker 方式安装。
在注册表中搜索 webllmchat ,选择第一个 wbsu2003/webllmchat,版本选择 latest。
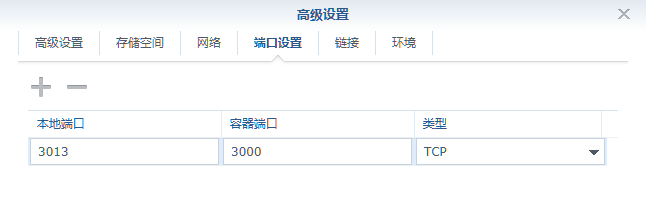
端口
本地端口不冲突就行,不确定的话可以用命令查一下
1 | # 查看端口占用 |
| 本地端口 | 容器端口 |
|---|---|
3013 |
3000 |
命令行安装
如果你熟悉命令行,可能用 docker cli 更快捷
1 | # 运行容器 |
也可以用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
1 | version: '3' |
然后执行下面的命令
1 | # 新建文件夹 webllmchat 和 子目录 |
运行
在浏览器中输入 https://webllmchat.laosu.tech 就能看到主界面,会有一个加载的过程
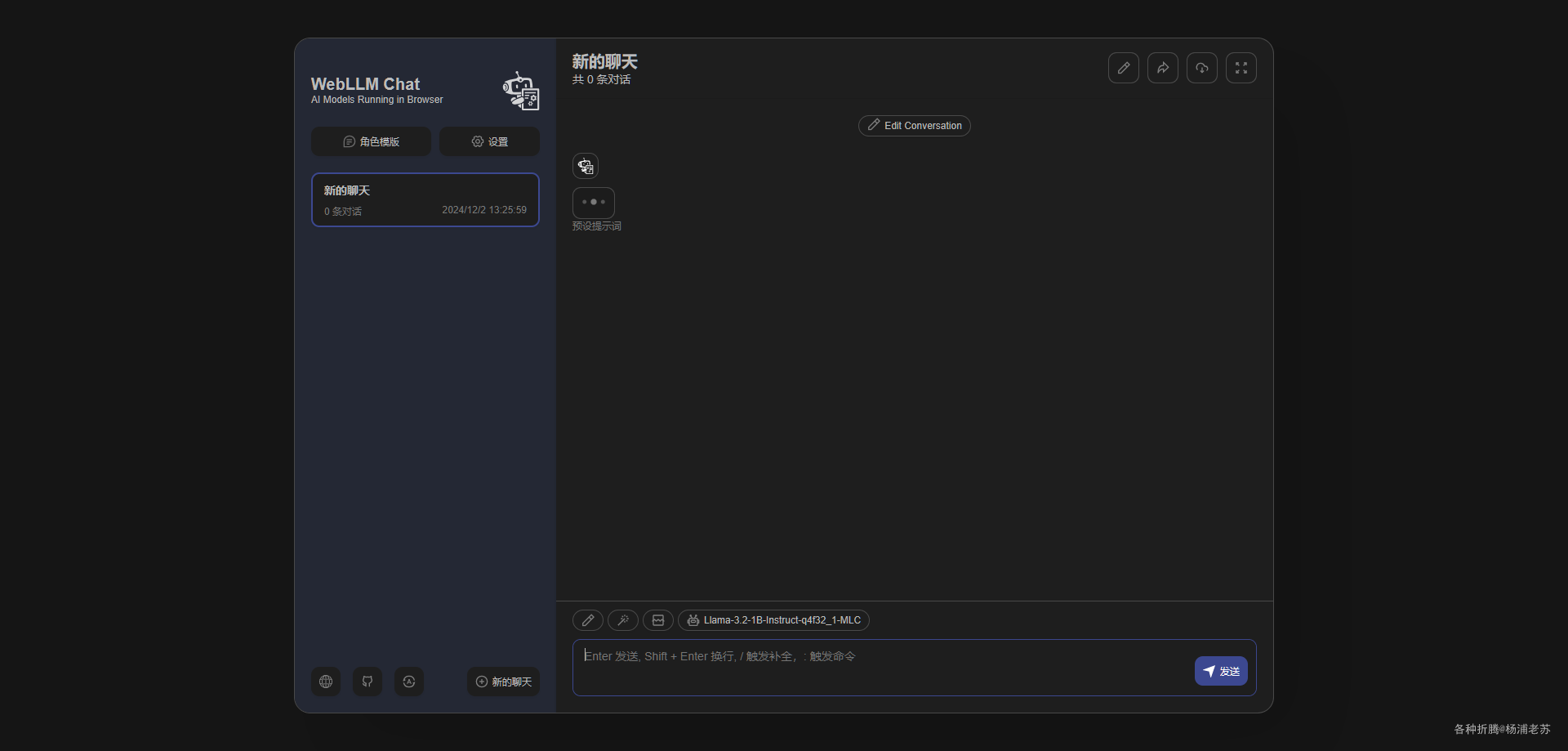
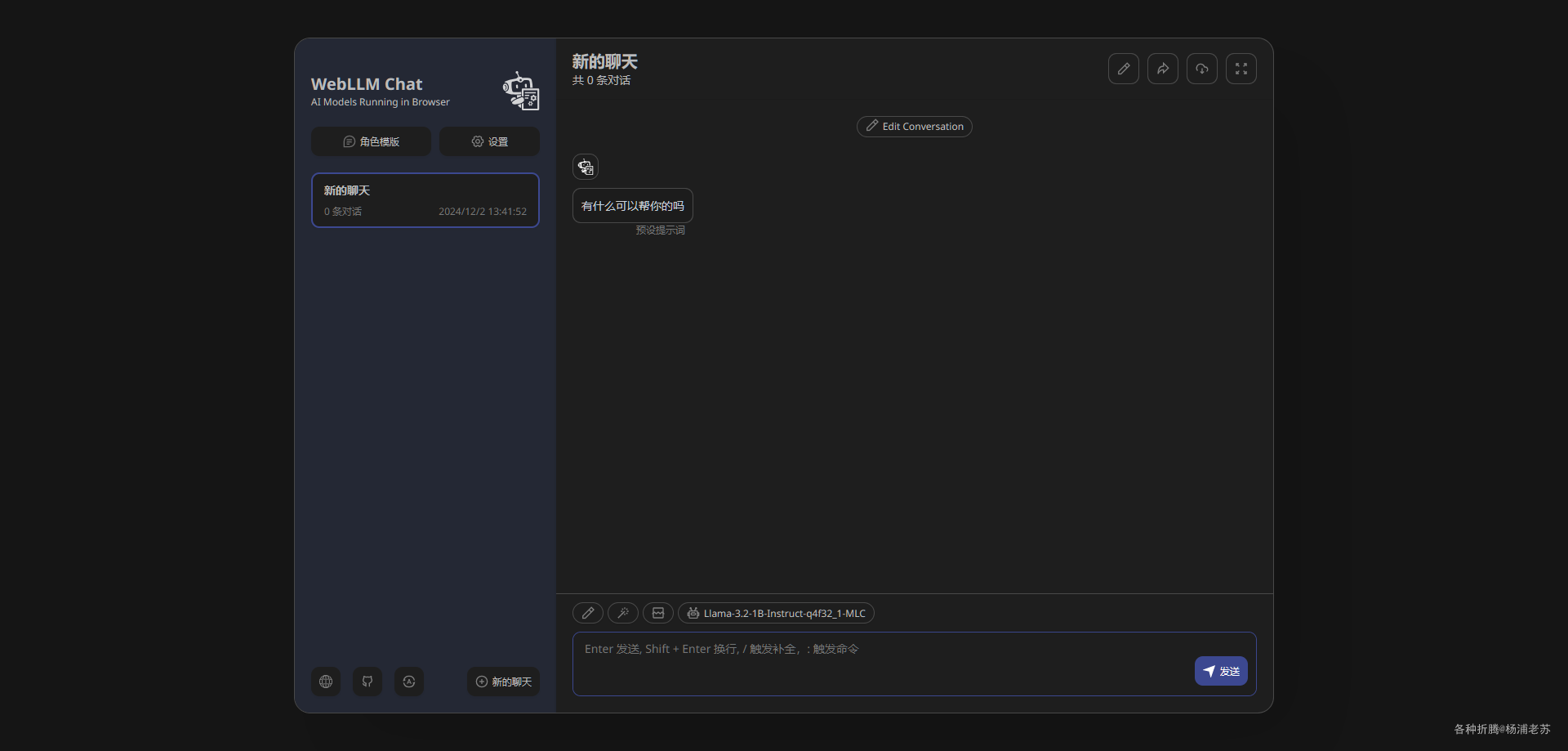
完成之后就可以开始提问了
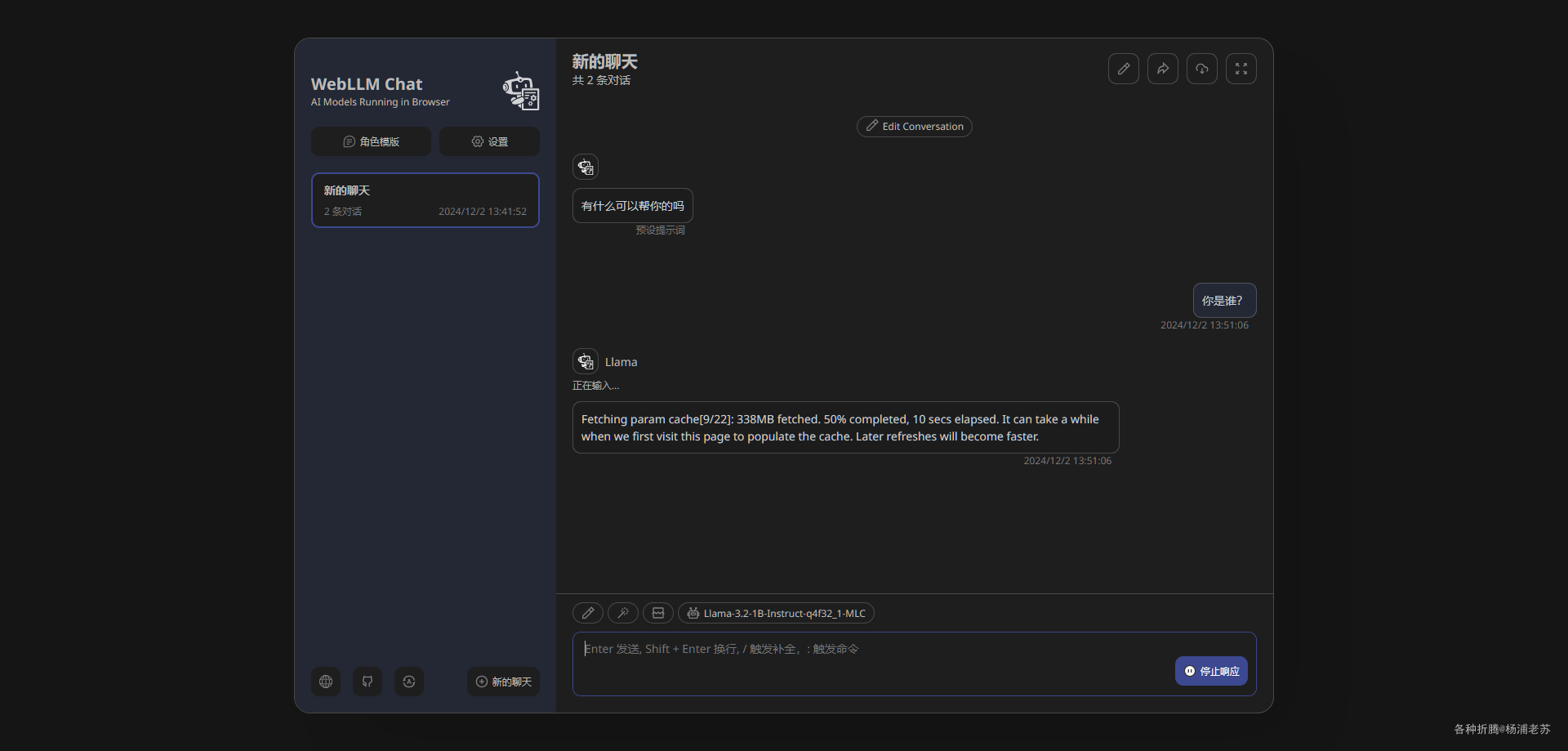
提问后,会开始下载模型
- 一旦模型文件下载完成,会被缓存,以便后续使用时能够更快地加载和运行。这种设计确保了用户在享受本地推理的同时,也能减少重复下载的时间和带宽消耗;
- 下载的模型在浏览器的开发者工具 –>
Application–>Cache storage–>webllm/model中找到;
下载完成后还需要加载,然后就能回答问题了
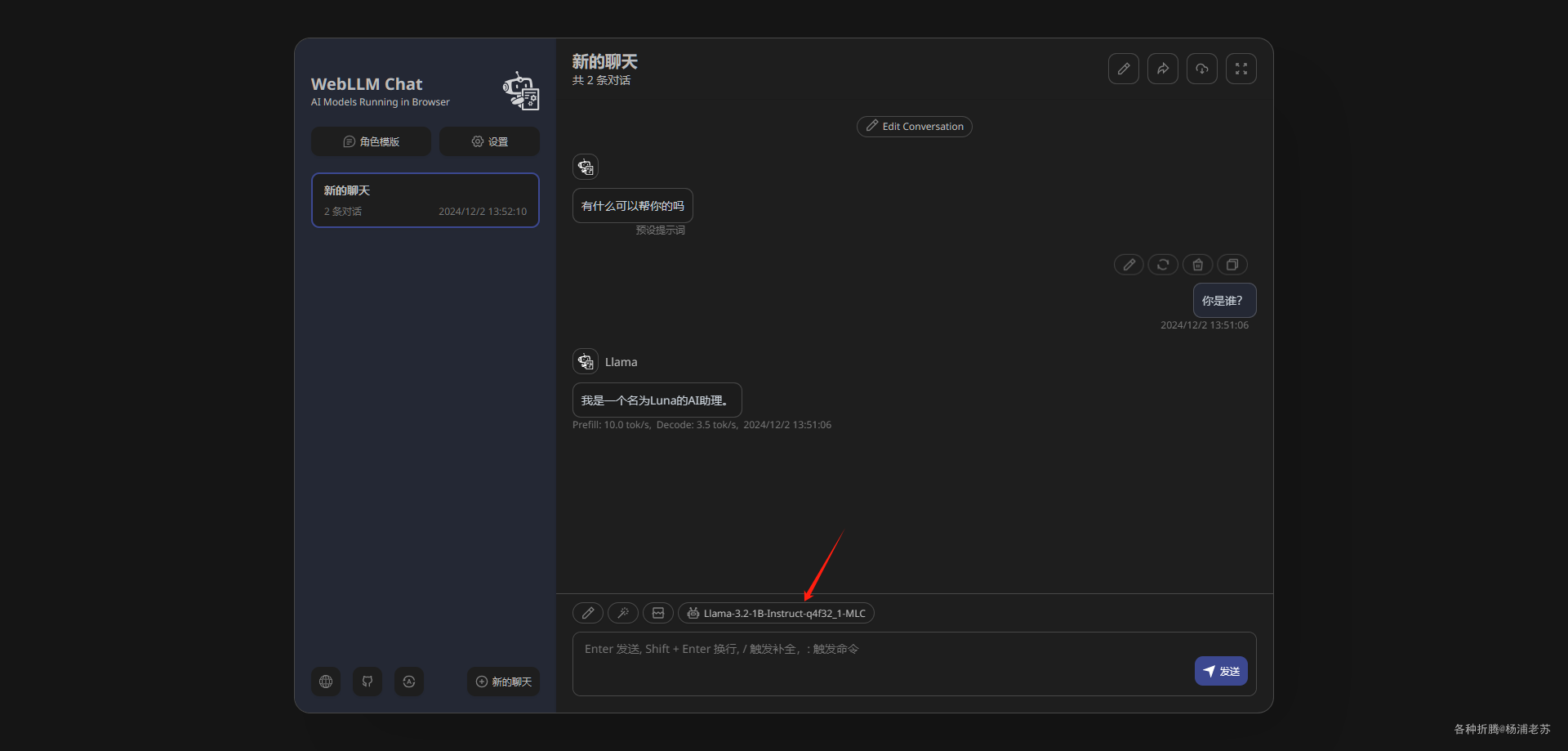
点模型,可以选择其他的模型
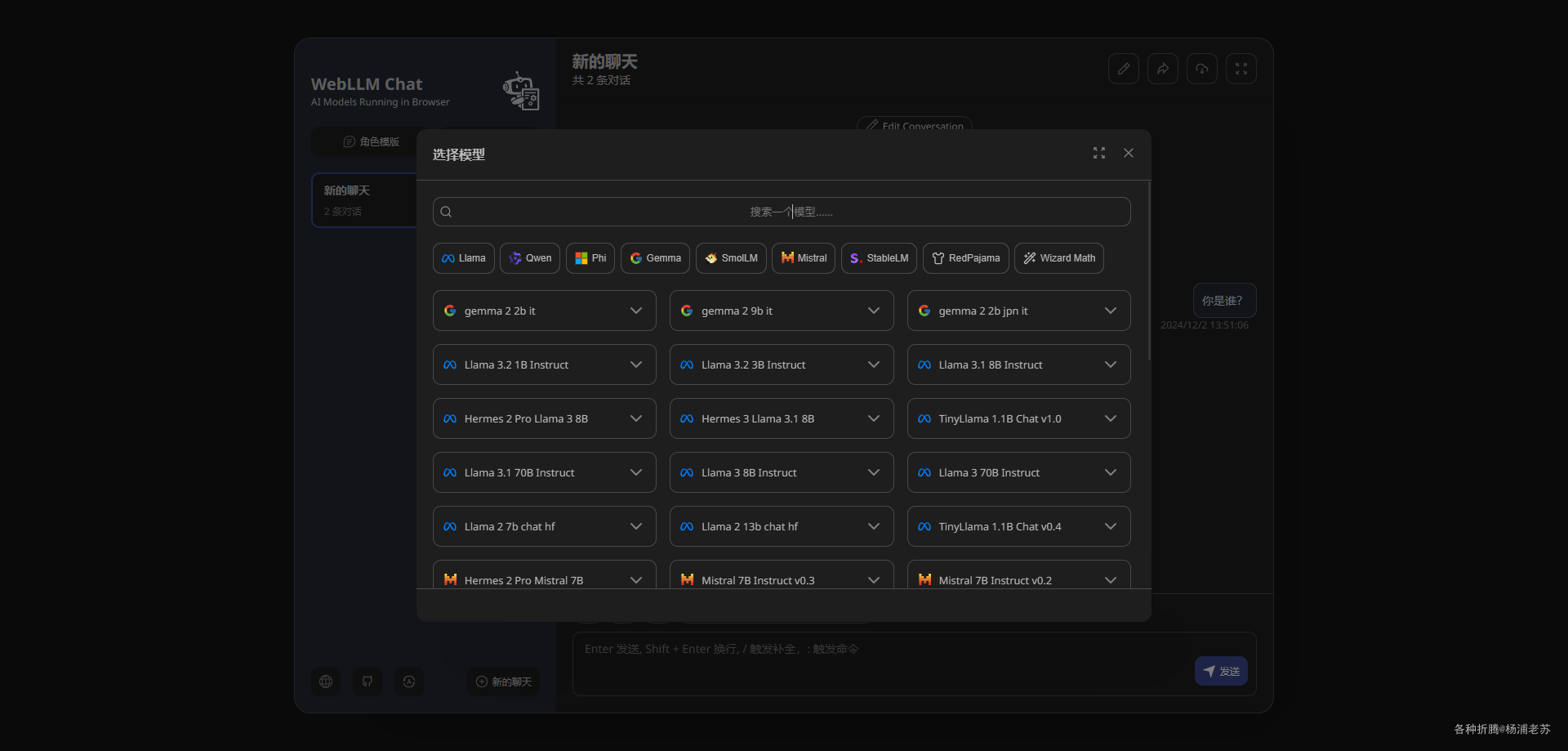
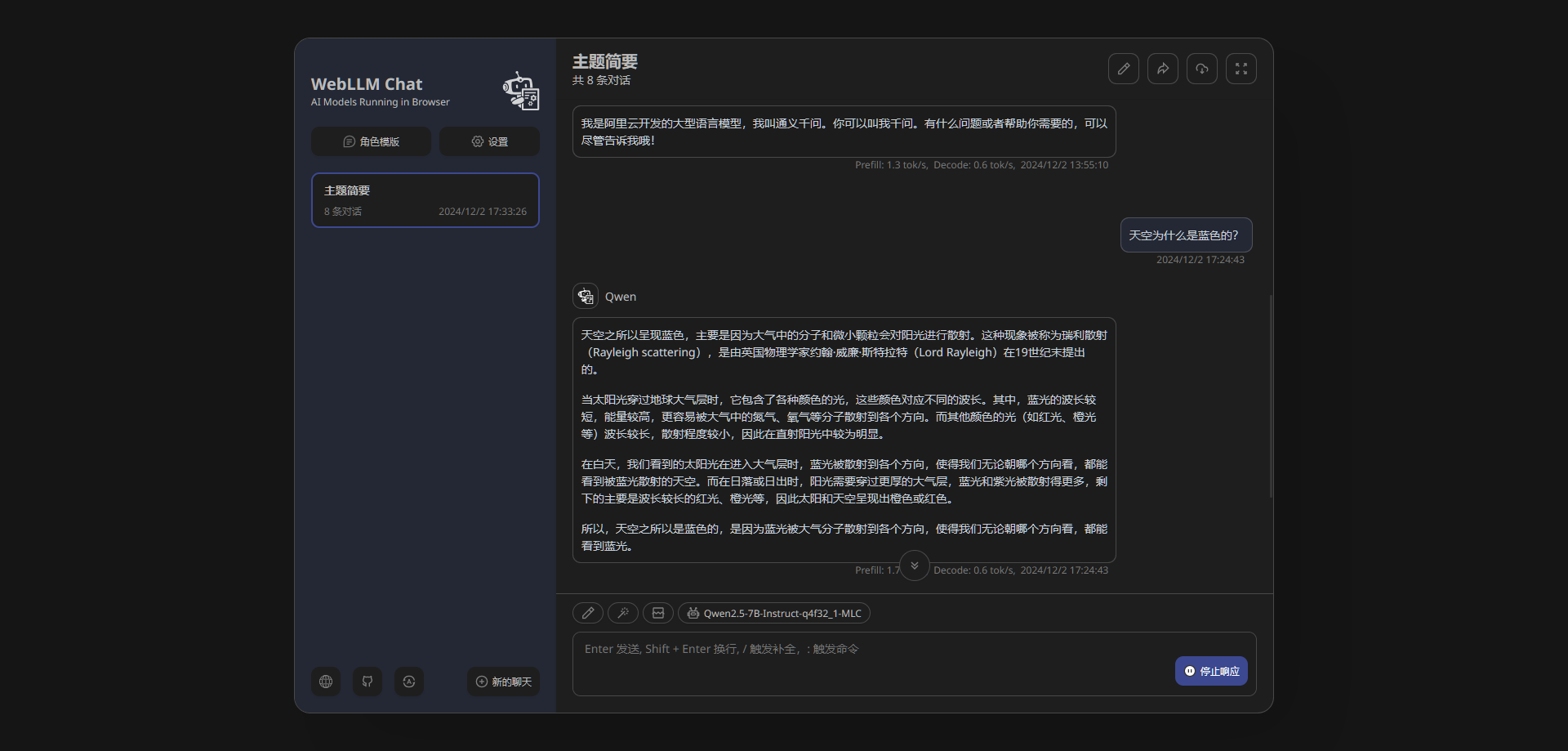
试试国产的 qwen2.5
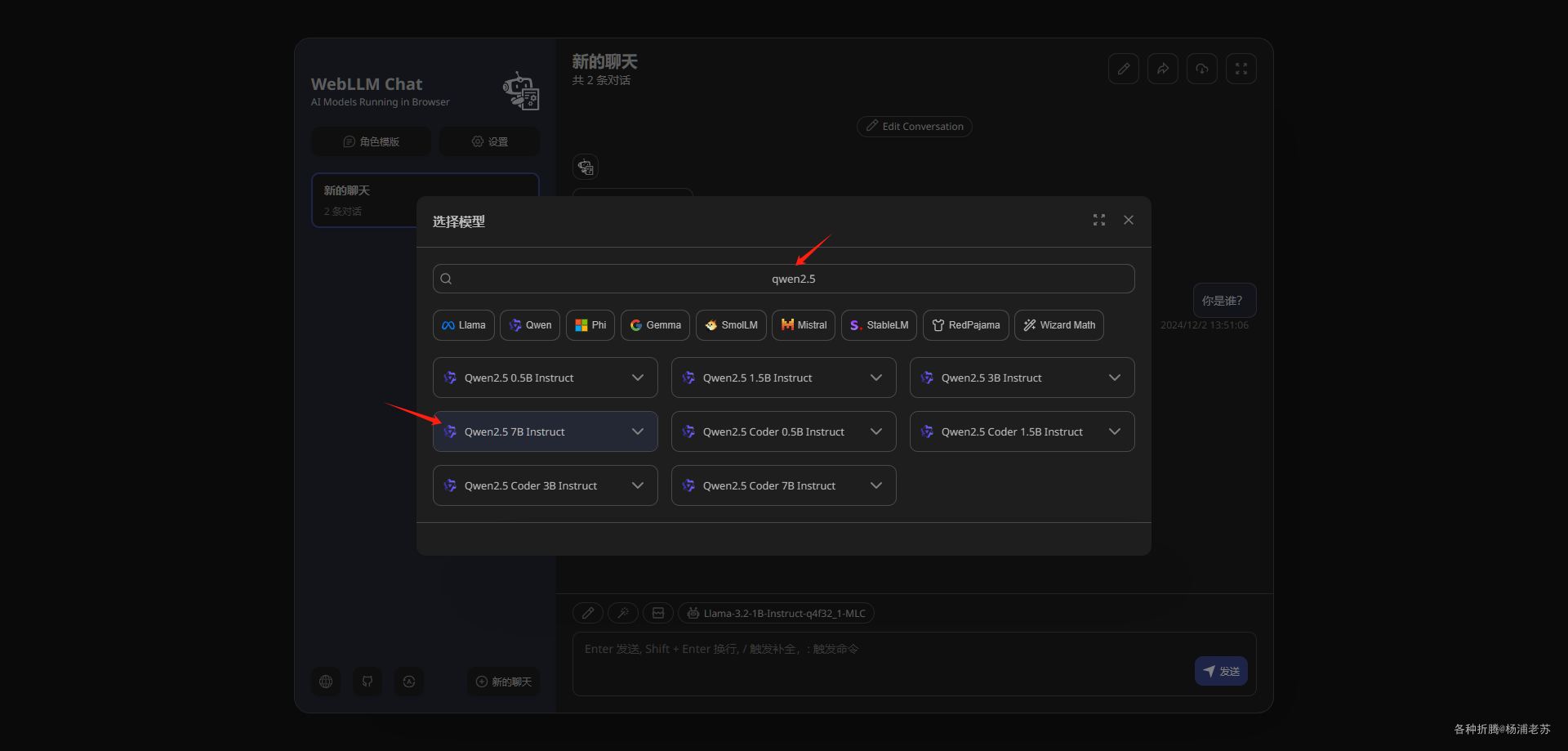
可以看到模型已经切换了
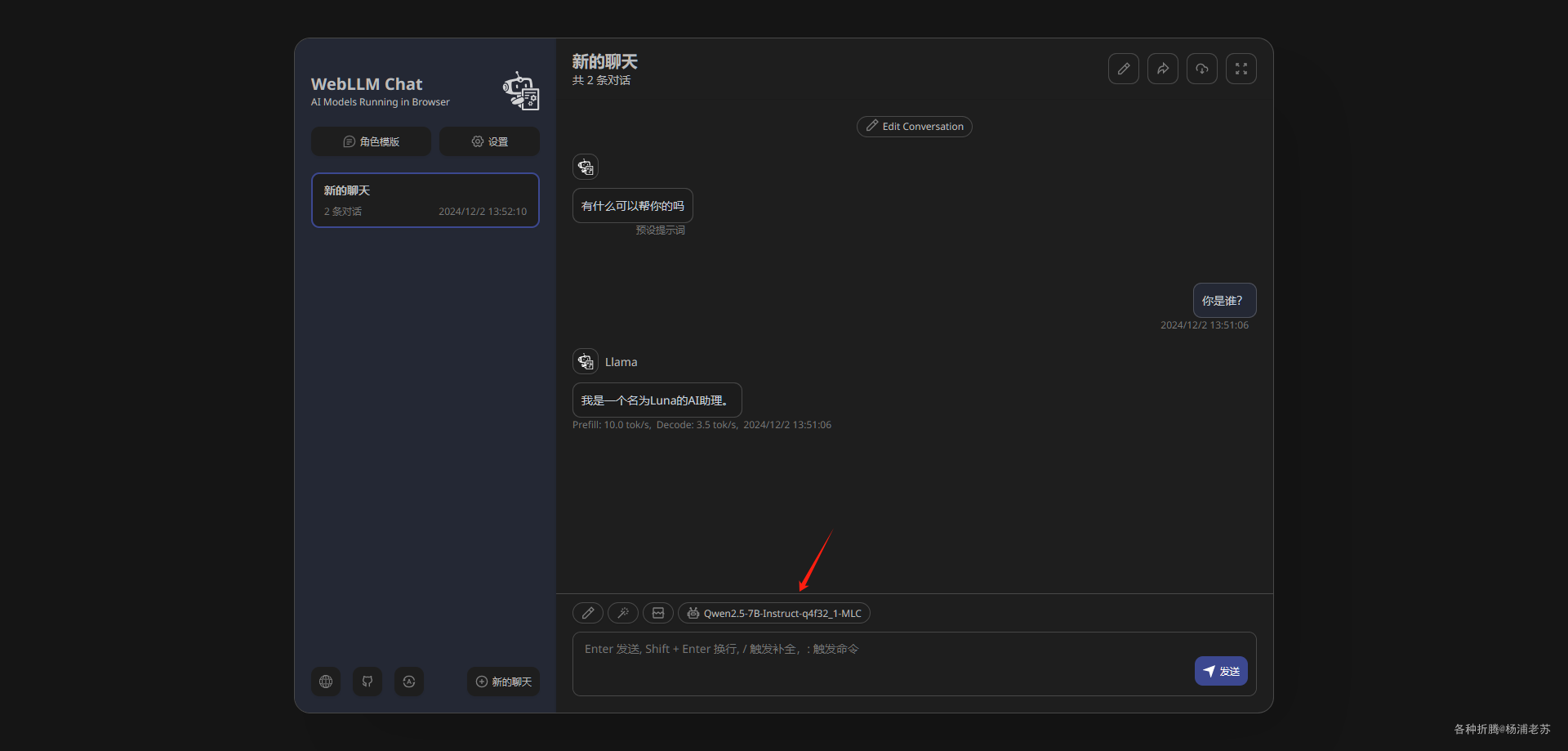
第一次还是需要下载,然后加载
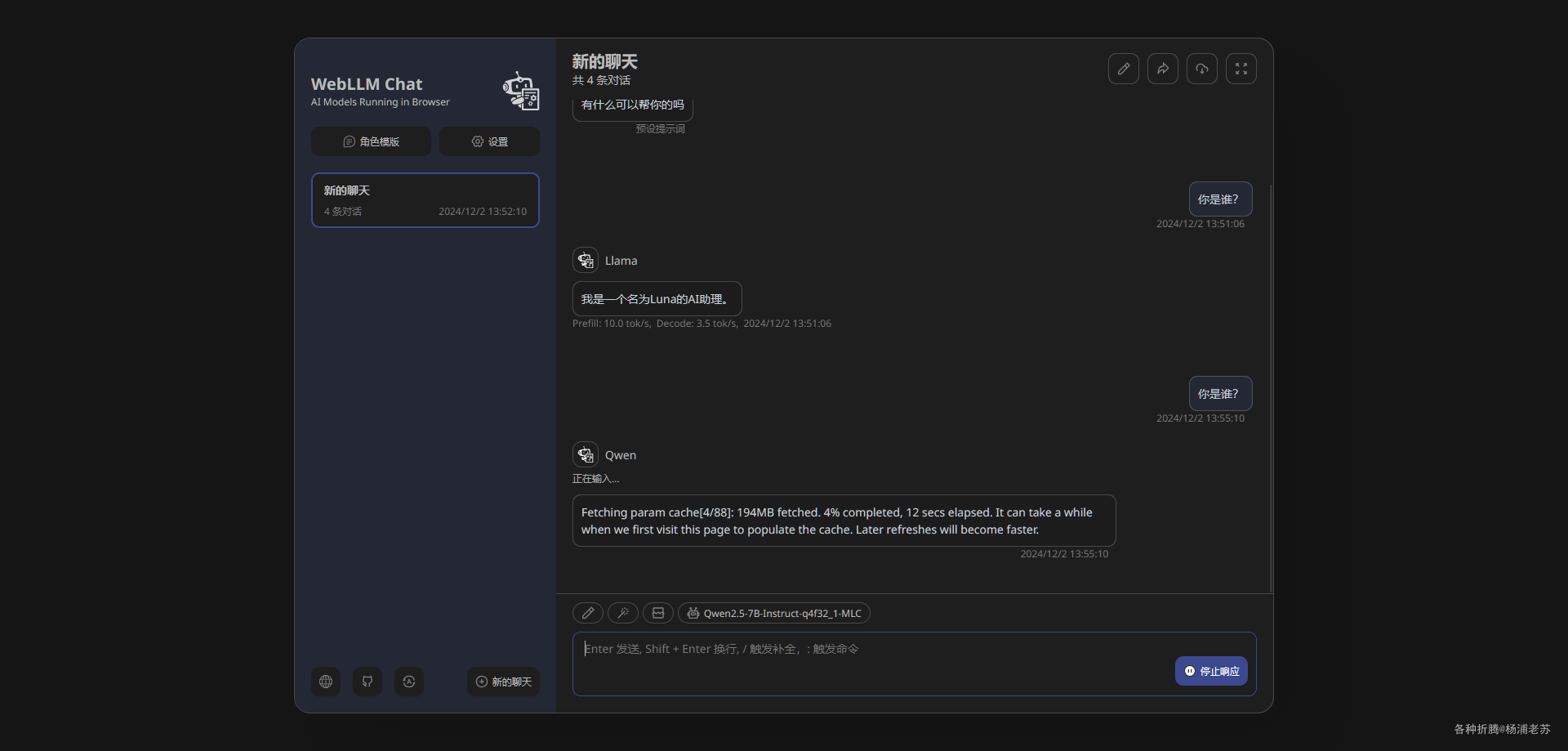
看得出来,启用了浏览器的 WebGPU
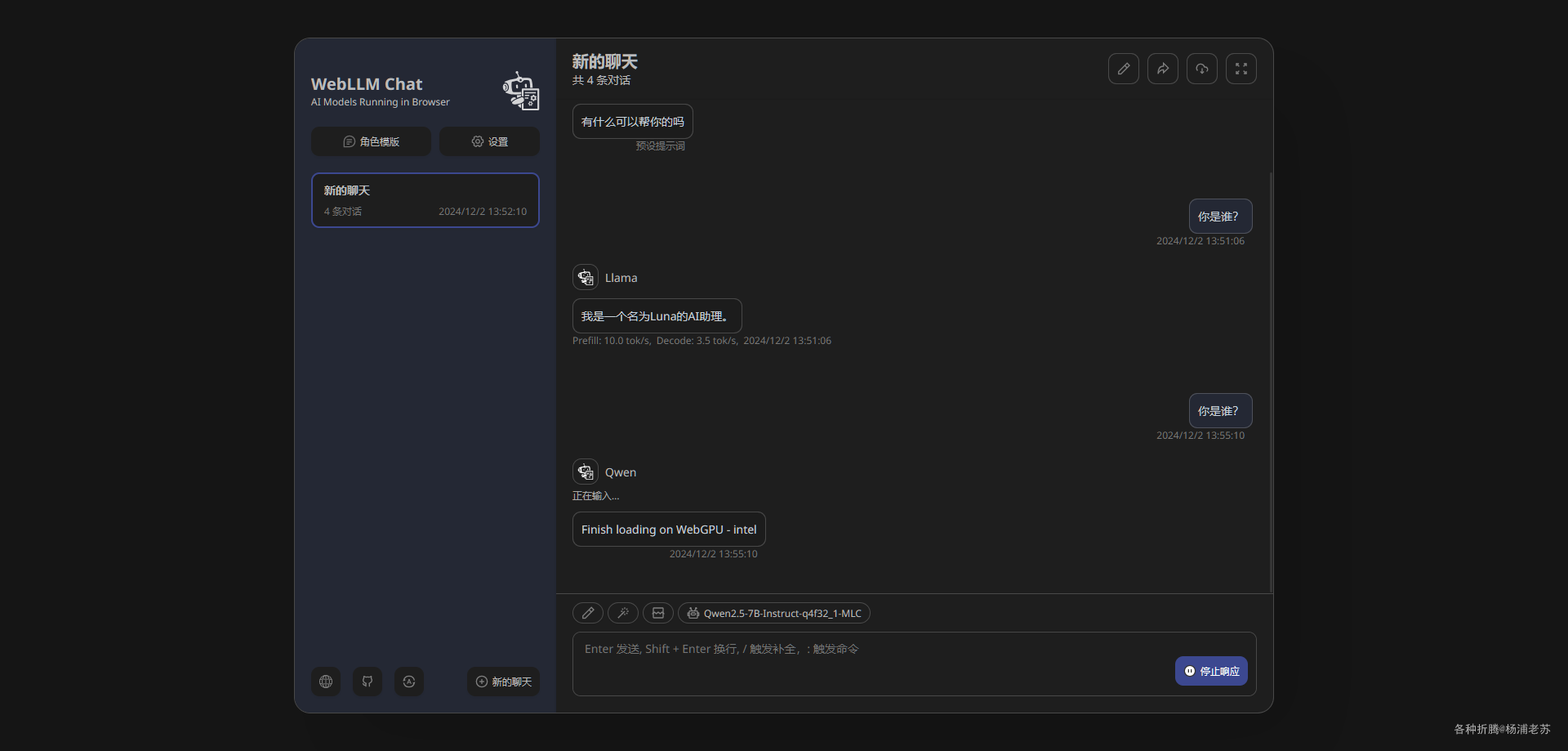
虽然台式机也比较古老,但是比用来跑群晖的笔记本平台还是性能强
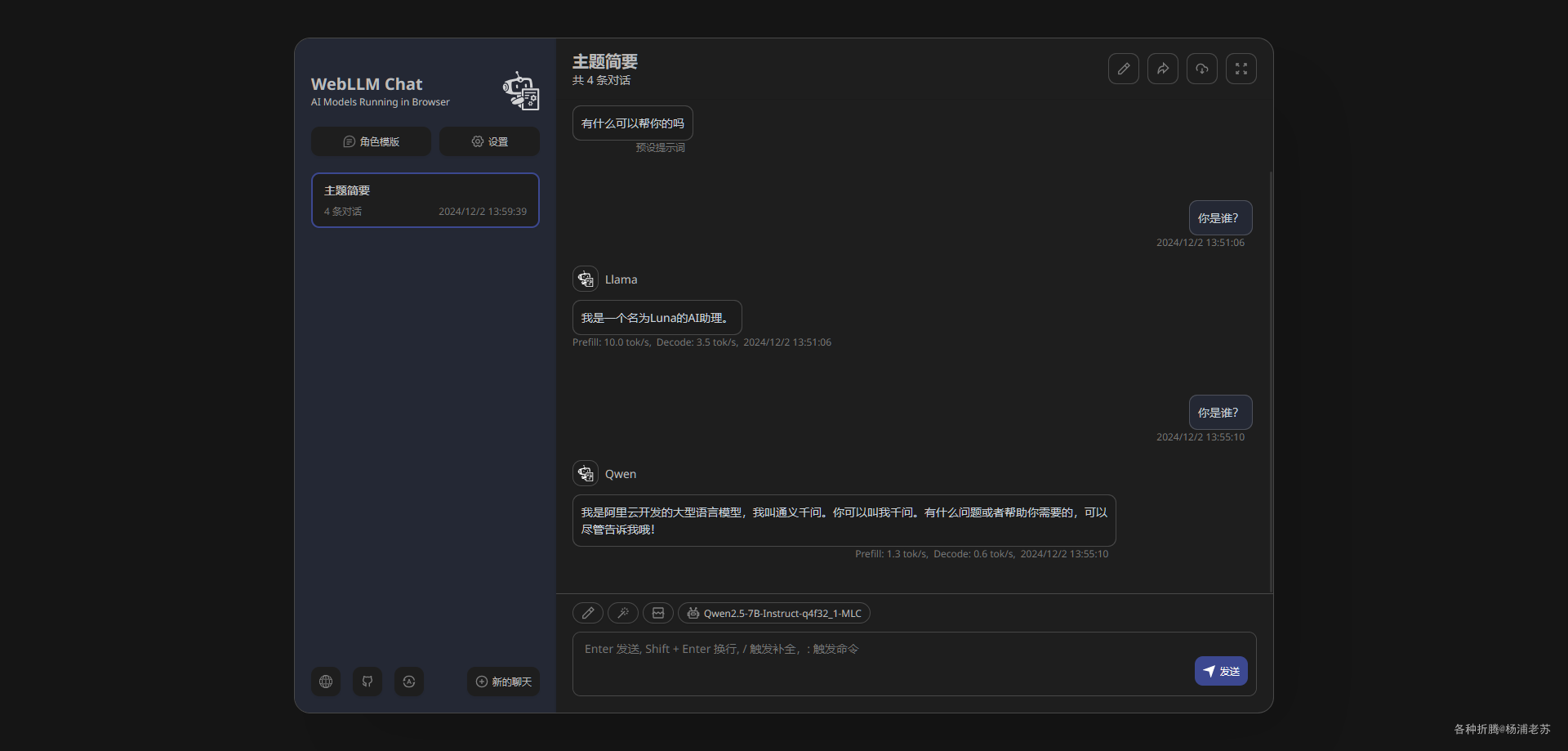
虽然慢一点,但起码 7b 也能跑起来
参考文档
mlc-ai/web-llm: High-performance In-browser LLM Inference Engine
地址:https://github.com/mlc-ai/web-llmmlc-ai/web-llm-chat: Chat with AI large language models running natively in your browser. Enjoy private, server-free, seamless AI conversations.
地址:https://github.com/mlc-ai/web-llm-chatWebLLM | Home
地址:https://webllm.mlc.ai/WebLLM Chat
地址:https://chat.webllm.ai/WebGPU Report
地址:https://webgpureport.org/