
能与文档聊天的RAG工具kotaemon
最近搞 AI 的项目比较多,正好看到硅基流动在送 Token,如果你用老苏的邀请链接注册, https://cloud.siliconflow.cn/i/NkUiXVhQ ,咱俩都能得 2000 万 Tokens ,虽然接口有点慢,但是用来测试软件还是挺好用的。
简介
什么是 RAG ?
RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的人工智能技术框架,主要用于提升自然语言处理(NLP)模型在处理复杂任务时的性能和准确性。它通过检索外部知识库中的信息,为生成模型提供更丰富的上下文和知识支持,从而生成更准确、更有信息量的内容。
什么是 Kotaemon ?
Kotaemon是一个开源的基于RAG(Retrieval-Augmented Generation)技术的工具,旨在帮助用户与文档进行交互和对话。
主要特点
- 自主托管文档问答(RAG)Web UI:支持多用户登录,可以组织您的文件为私有/公共集合,协作并与他人分享您最喜欢的聊天记录。
- 组织您的 LLM 和嵌入模型:支持本地
LLM和流行的API提供商(如OpenAI、Azure、Ollama、Groq)。 - 混合 RAG 流水线:提供合理的默认
RAG流水线,结合全文本和向量检索器,并进行重新排序,以确保最佳的检索质量。 - 多模态问答支持:在多个文档上进行问答,支持图表和表格。支持多模态文档解析(在
UI上可选择的选项)。 - 高级引用与文档预览:系统默认提供详细的引用,以确保
LLM答案的正确性。在浏览器内的PDF查看器中直接查看您的引用(包括相关评分),并对低相关性文章的检索管道发出警告。 - 支持复杂推理方法:使用问题分解来回答复杂的多跳问题。支持基于代理的推理,如
ReAct、ReWOO和其他代理。 - 可配置设置 UI:可以在
UI上调整检索和生成过程中的大多数重要方面(包括提示)。 - 可扩展性:基于
Gradio构建,您可以自由自定义或添加任何UI元素。此外,我们旨在支持多种文档索引和检索策略。GraphRAG索引流水线作为示例提供。

Kotaemon适合希望进行文档管理和问答的终端用户,以及希望构建定制化解决方案的开发者。
准备
因为会用到 LLMs 模型和 Embeddings 模型,所以需要提前准备。下面是可能会用上的模型和工具,请根据需要,选择性进行安装
文章传送门:
本次老苏使用的是 One API 管理的 kimi-free-api 和 Ollama 中安装的nomic-embed-text
安装
在群晖上以 Docker 方式安装。
官方的镜像发布在 ghcr.io
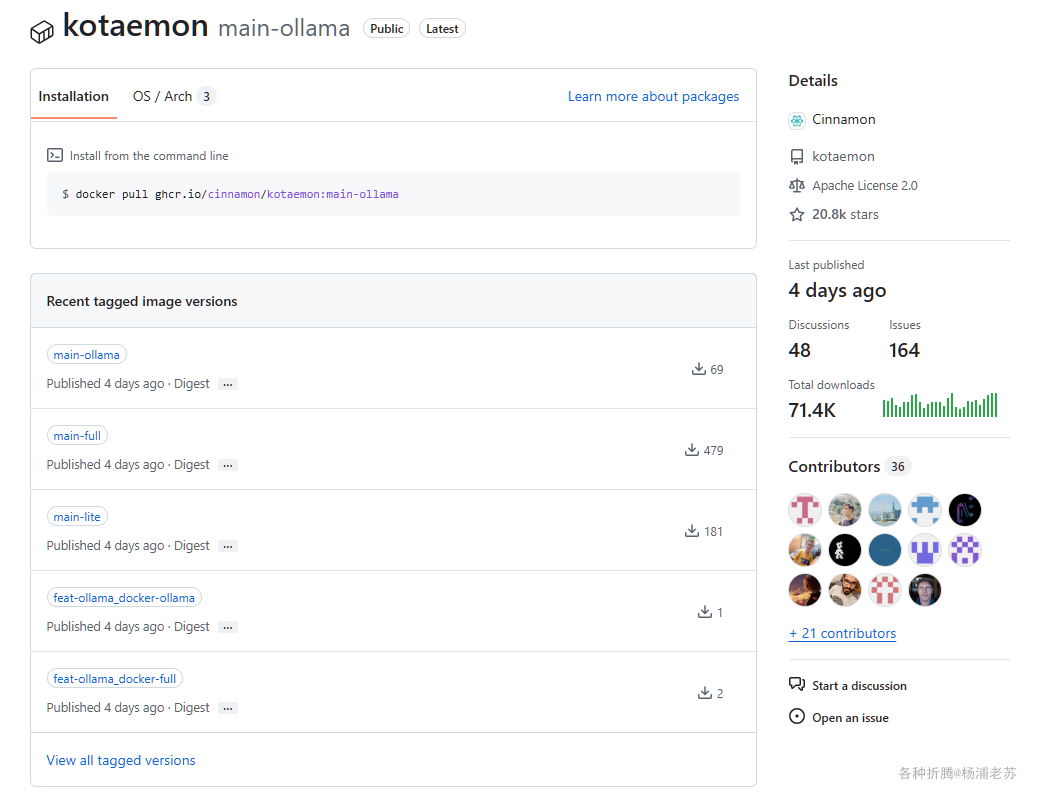
ghcr.io/cinnamon/kotaemon:main-lite版本是精简版,适合大多数用户。- 若需支持更多文件类型(如
.doc、.docx等),可使用ghcr.io/cinnamon/kotaemon:main-full,代价是docker镜像大小更大
docker cli 安装
如果你熟悉命令行,可能用 docker cli 更快捷
1 | # 运行容器 |
关于环境变量的简单说明
| 可变 | 值 |
|---|---|
GRADIO_SERVER_NAME |
指定允许从任何 IP 地址访问 Gradio 界面 |
GRADIO_SERVER_PORT |
定义 Gradio 应用程序监听的端口 |
更多环境变量,可以参考官方的 .env.example 文件,地址:https://github.com/Cinnamon/kotaemon/blob/main/.env.example
docker-compose 安装
也可以用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
1 | version: '3' |
然后执行下面的命令
1 | # 新建文件夹 kotaemon 和 子目录 |
运行
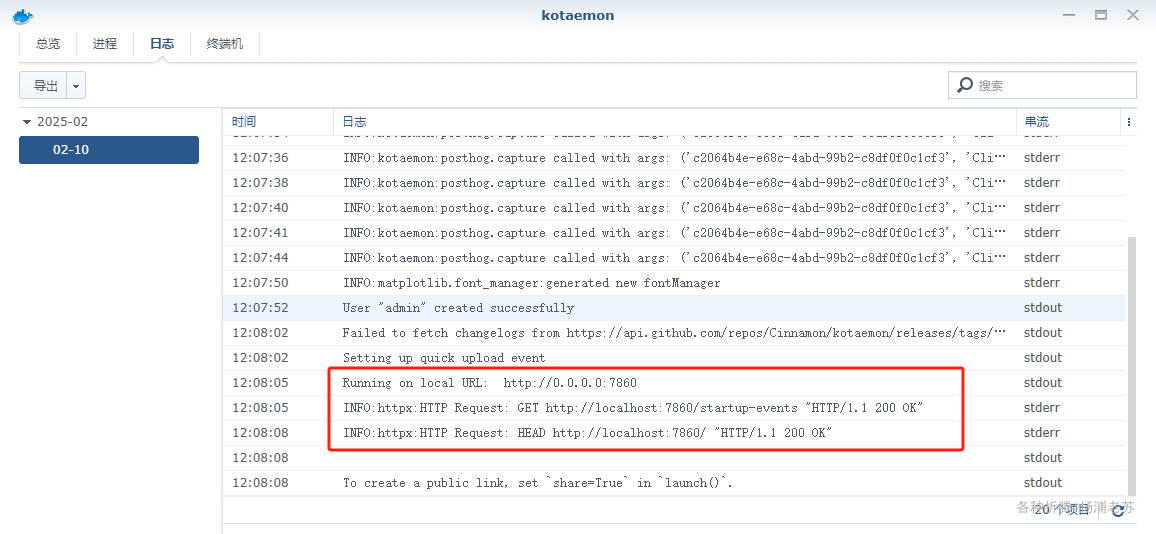
初始化需要时间,当在日志中看到下面的内容,说明 kotaemon 已经就绪了
1 | Running on local URL: http://0.0.0.0:7860 |
在浏览器中输入 http://群晖IP:7860 就能看到设置界面
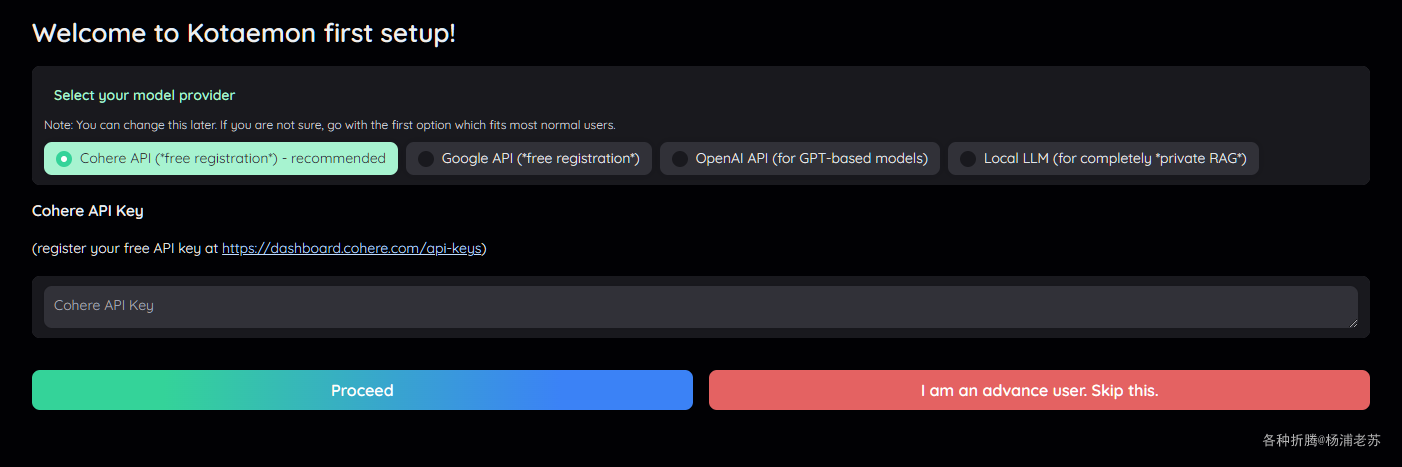
选择 I am an advance user. Skip this. 先直接跳过
添加 LLM 模型
Resources –> LLMs –> Add,这里使用了 One API 管理的 kimi-free-api
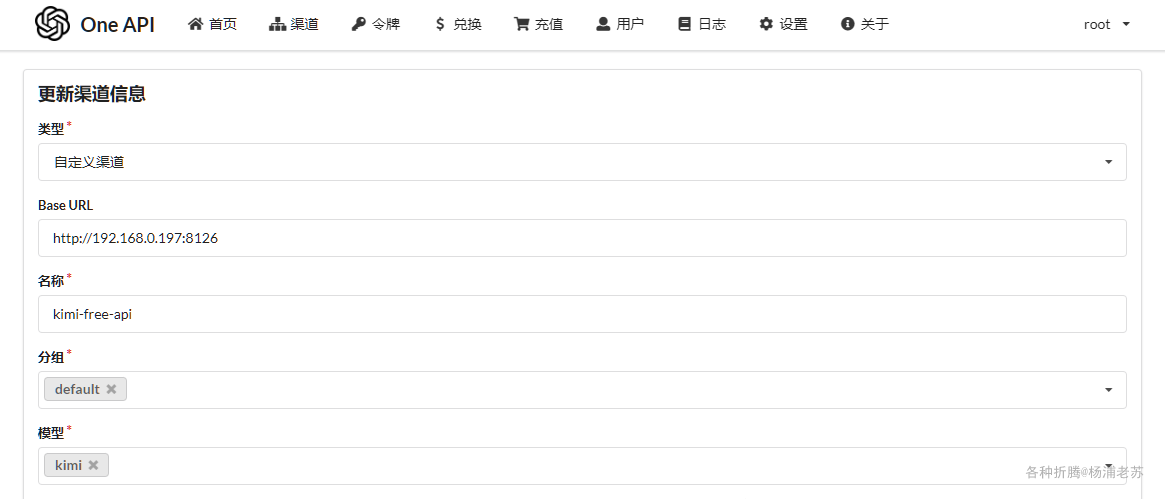
LLM name:例如kimiLLM vendors:下拉选择ChatOpenAISpecification:填入必要的参数,主要是下面三个,更多参数可以阅读右侧的表格
| 参数 | 描述 |
|---|---|
base_url |
One API 的地址 |
api_key |
One API 的令牌 |
model |
One API 中定义的模型名称 |
1 | base_url: http://192.168.0.197:3033/v1 |
- 勾选
Set default
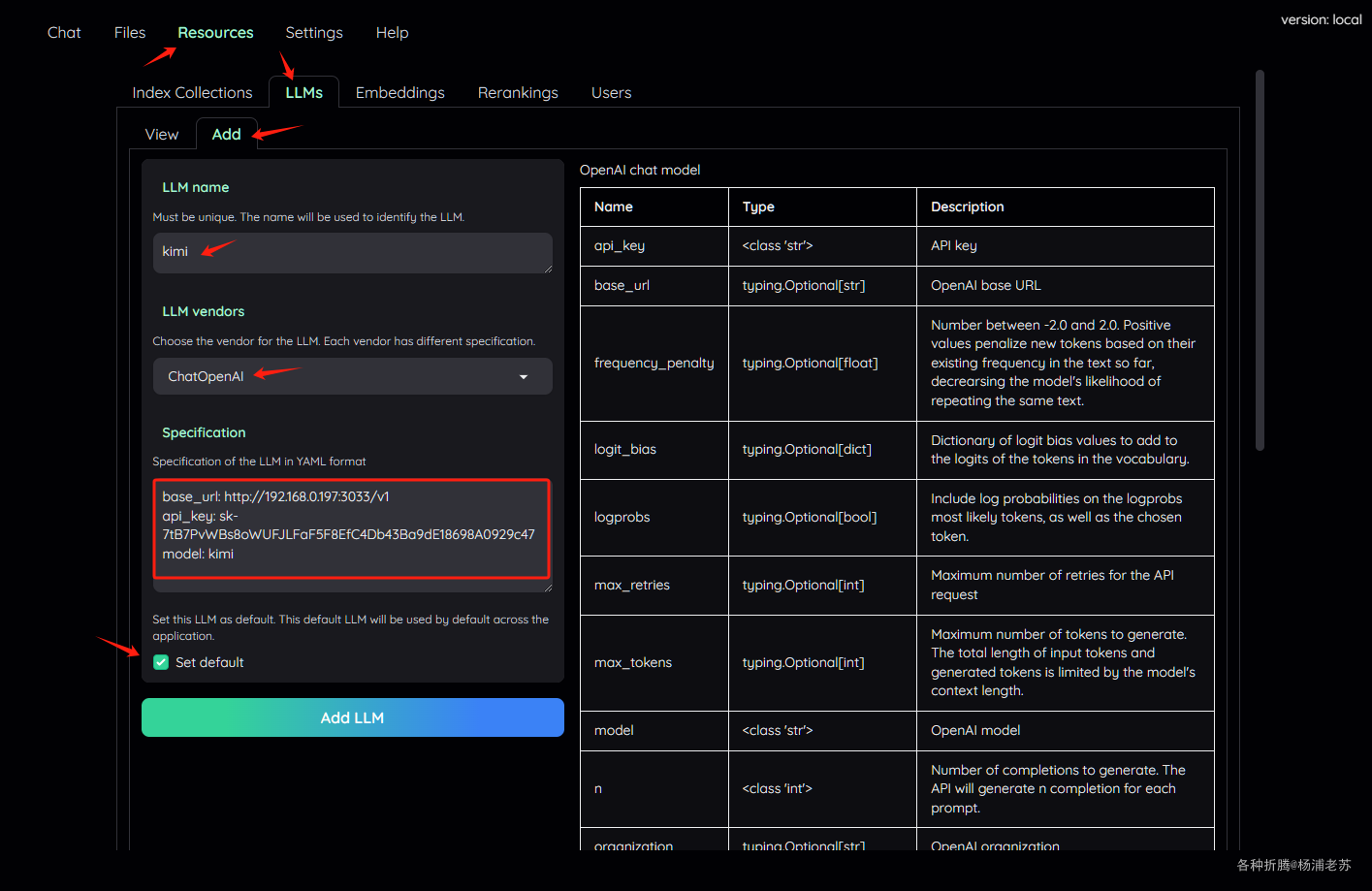
点 Add LLM 添加成功后,切换到 View ,找到 kimi
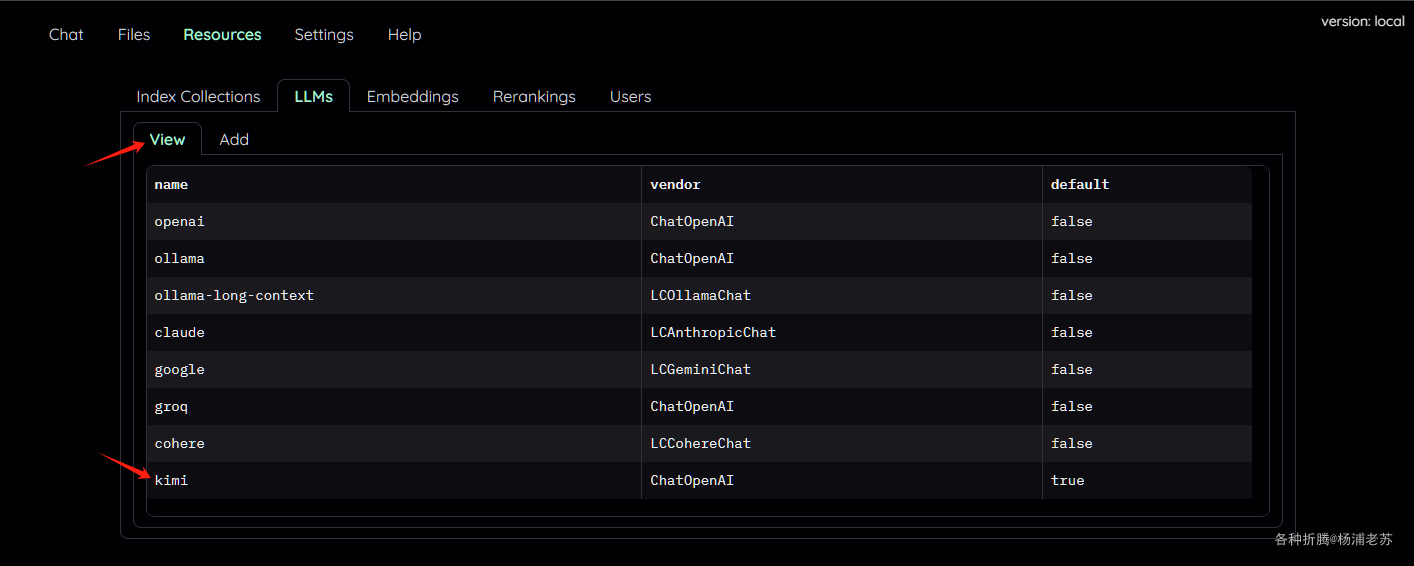
点击打开后,找到 Test 按钮
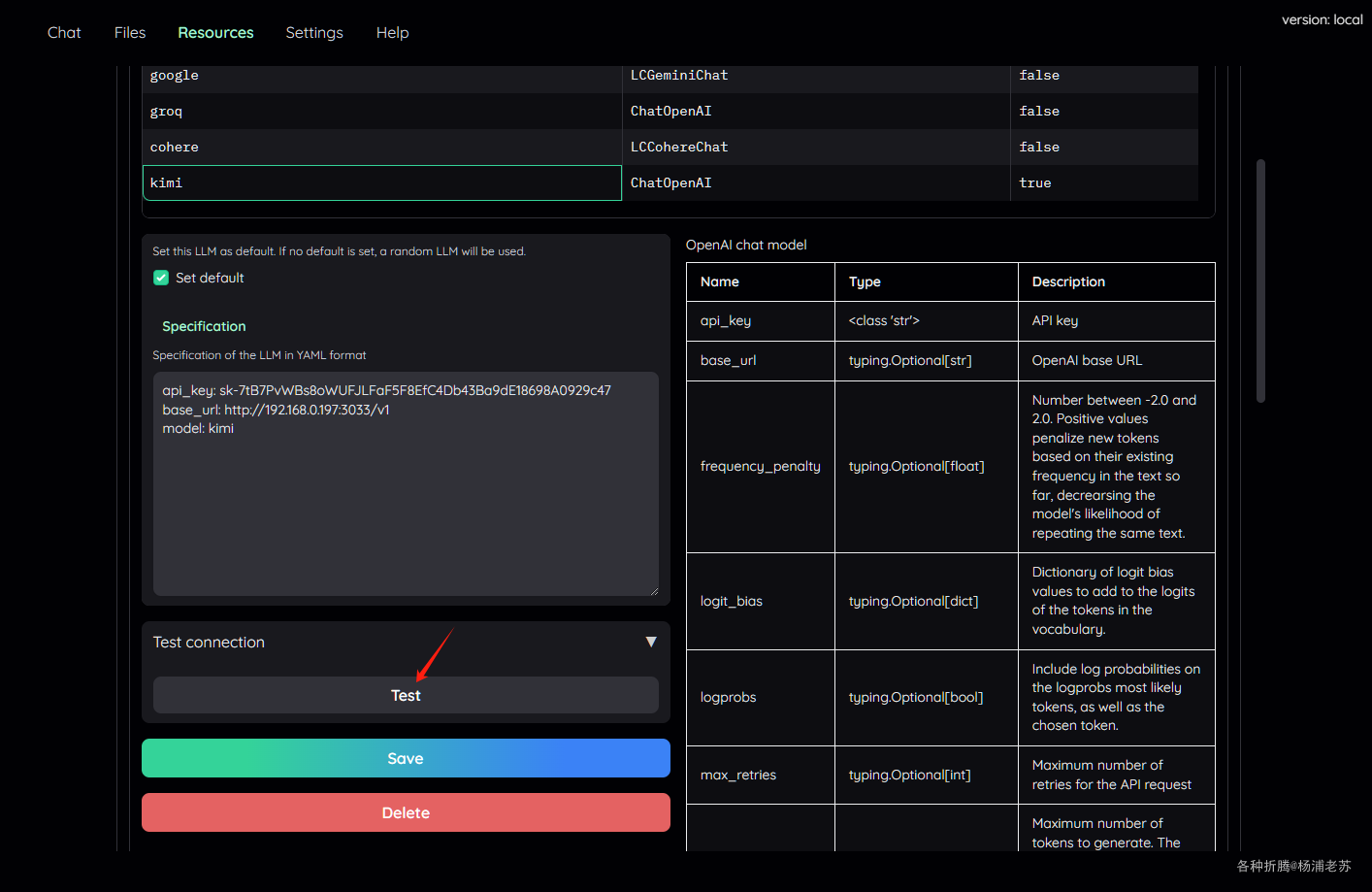
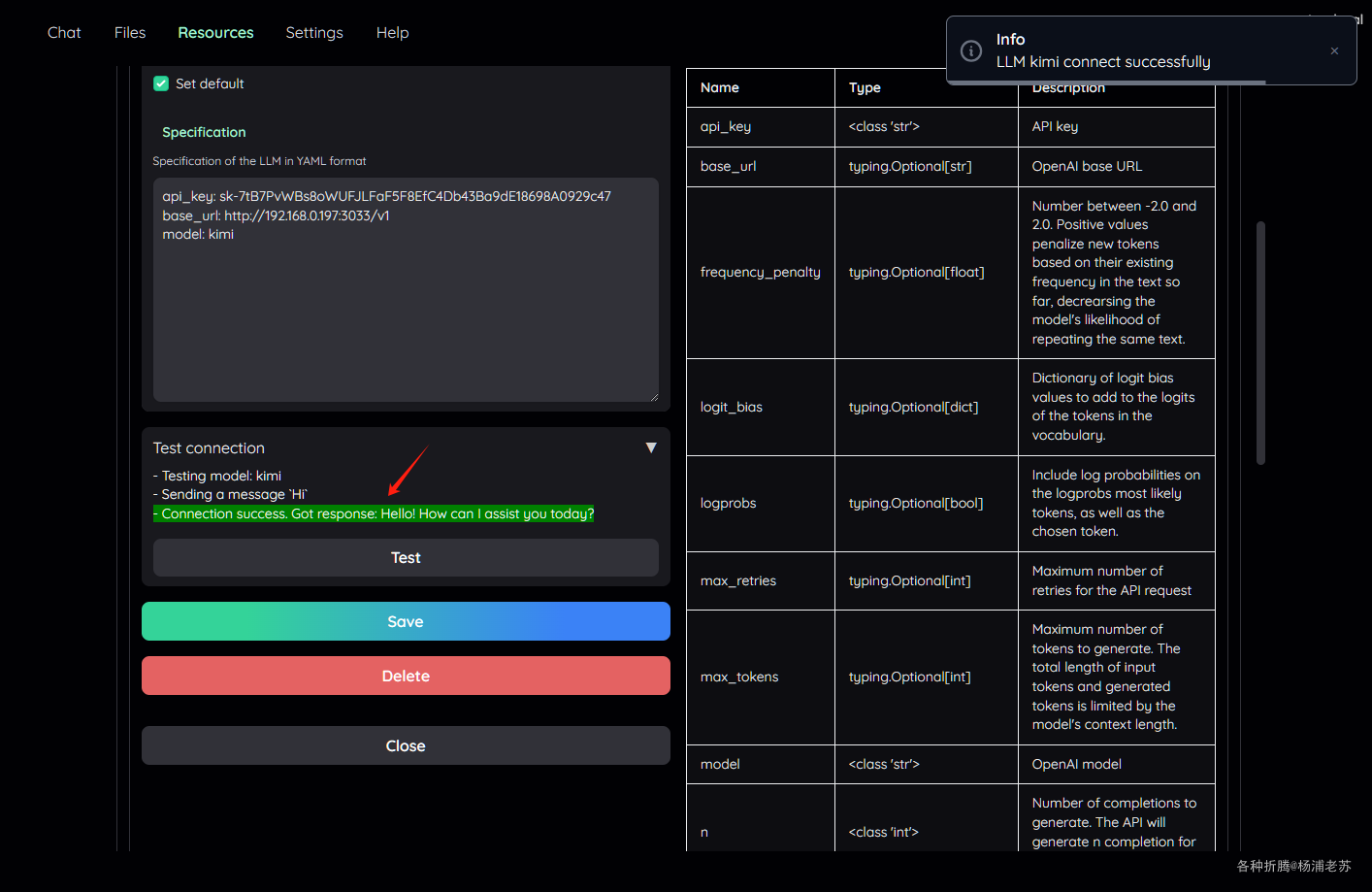
如果显示 Connection success,说明添加成功了
添加 Embeddings 模型
和添加 LLMs 模型差不多,Resources –> Embeddings –> Add,这里直接使用了 Ollama 管理的 nomic-embed-text
Name:只是用于区别,所以随便起了一个nomic-embed-textVendors:下拉选择OpenAIEmbeddingsSpecification:填入必要的参数,主要是下面三个,更多参数可以阅读右侧的表格
| 参数 | 描述 |
|---|---|
base_url |
Ollama 的地址 |
api_key |
Ollama 没有令牌,所以这里可以随便输入 |
model |
Ollama 中下载的嵌入文本模型 |
1 | base_url: http://192.168.0.197:11434/v1/ |
- 勾选
Set default
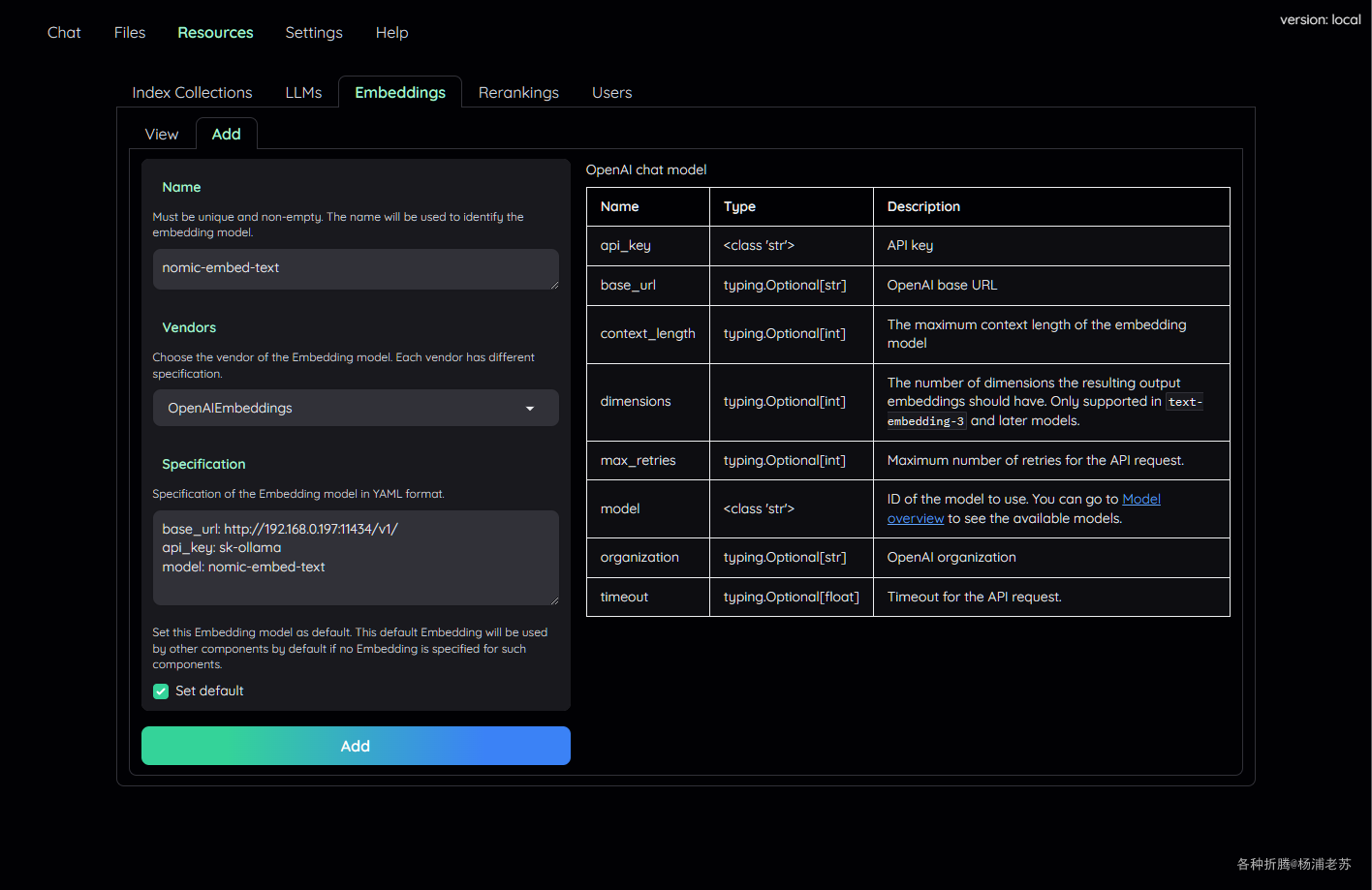
点 Add 添加成功后
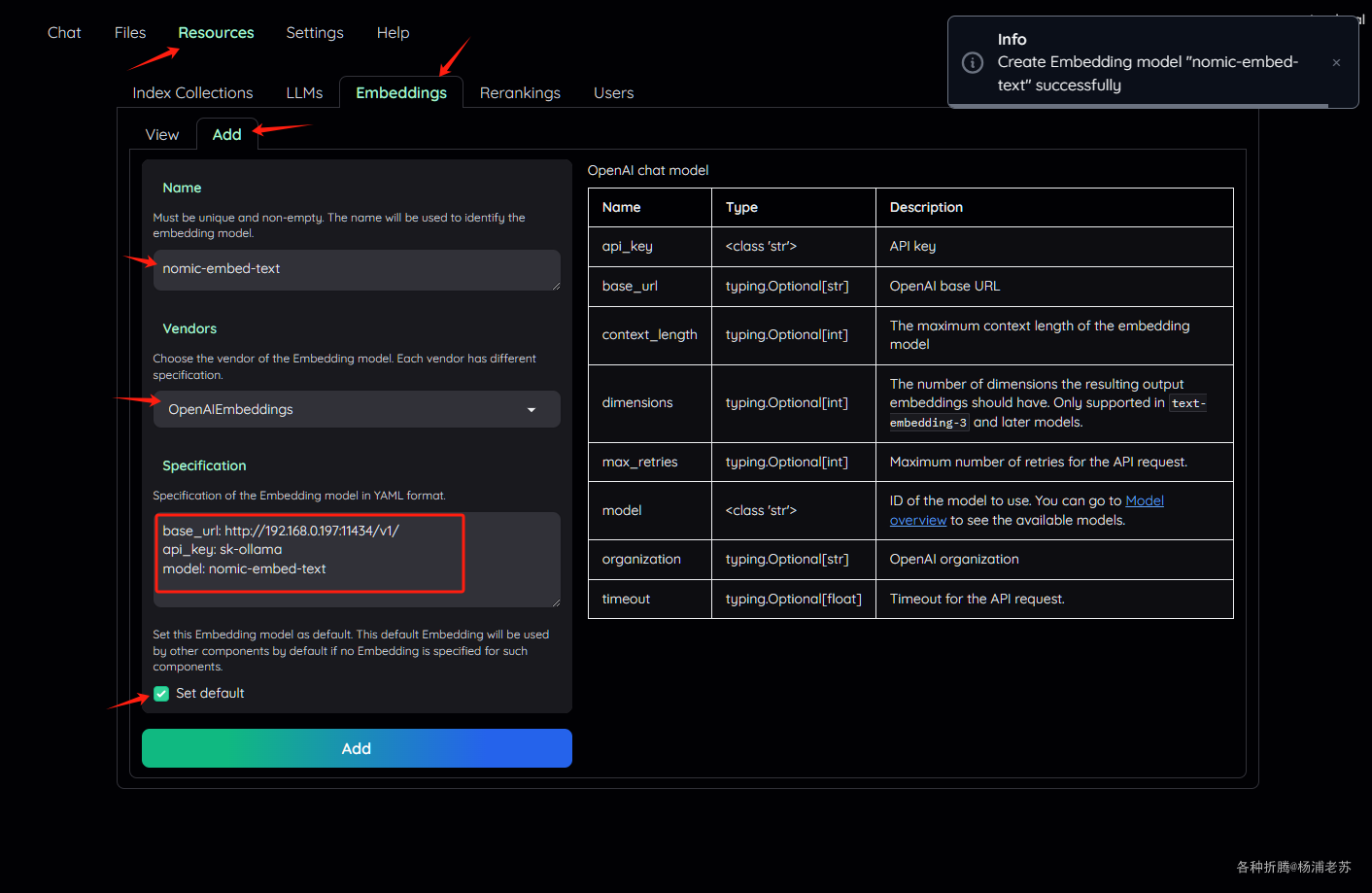
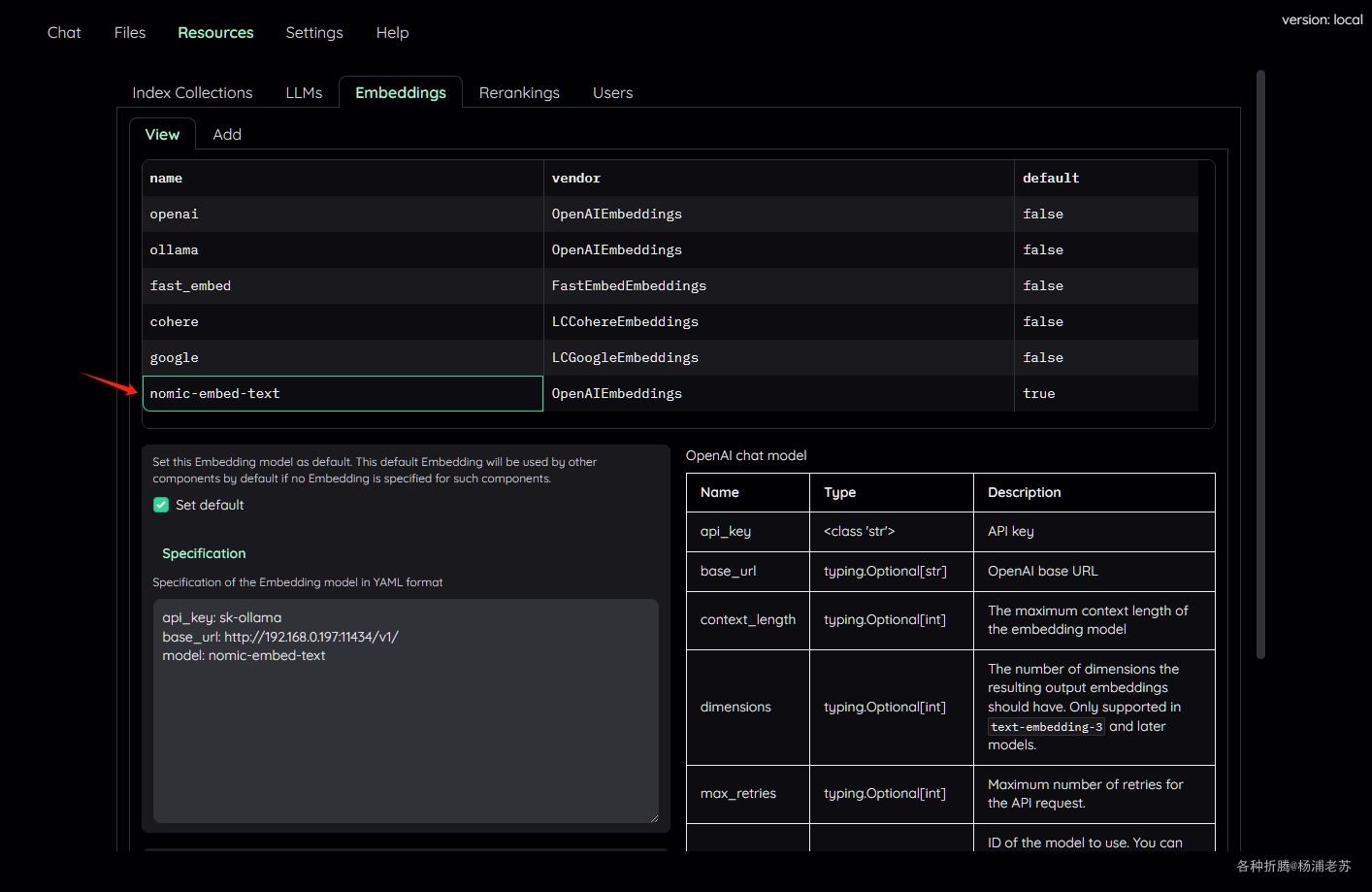
切换到 View ,找到 nomic-embed-text
下拉找到 Test,如果显示 Connection success,说明添加成功了
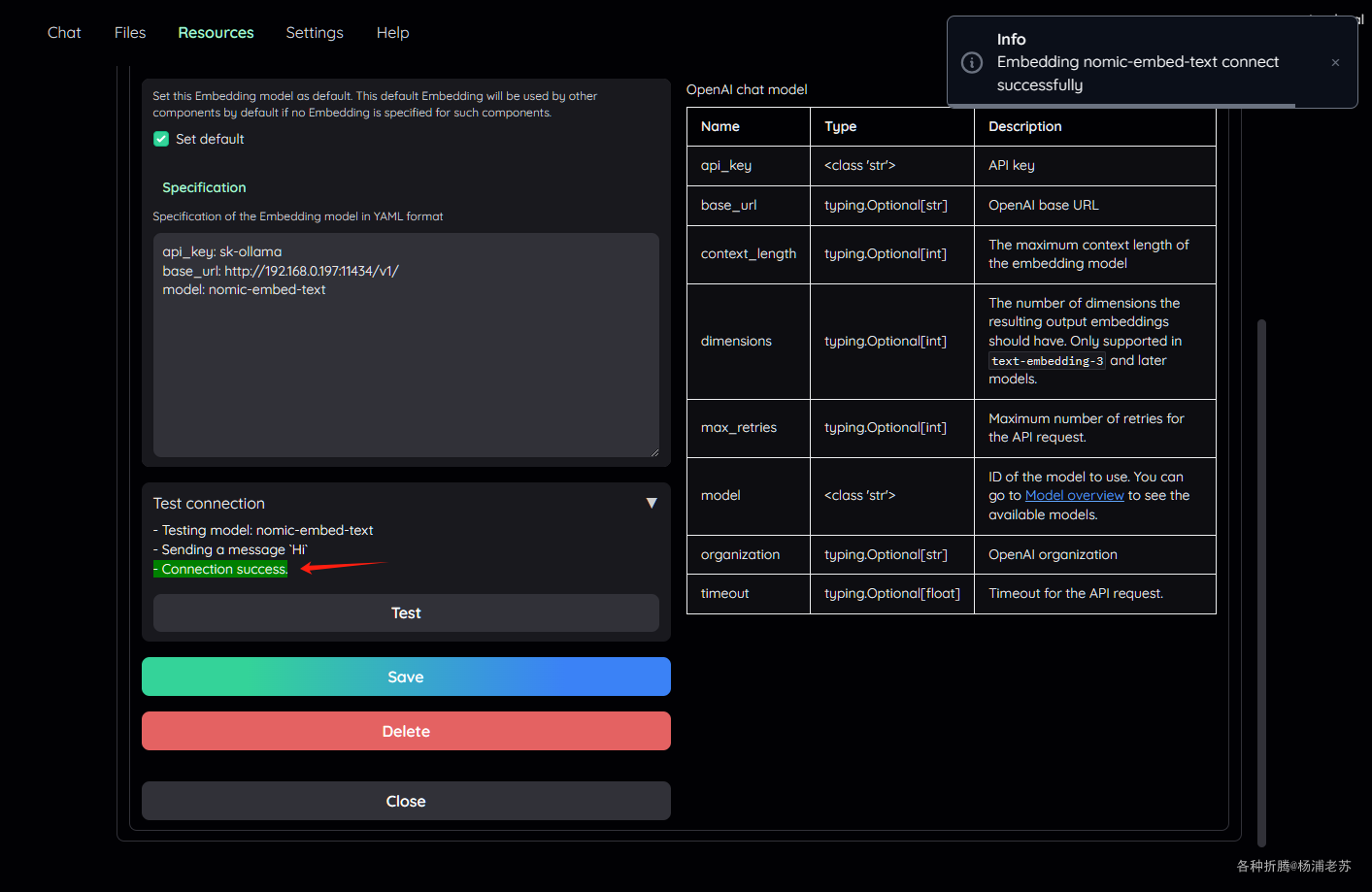
一定要测试,确保设置无误,否则有可能上传文档会报错的
1 | enacity.RetryError: RetryError[<Future at 0x7f5330250280 state=finished raised InternalServerError>] |
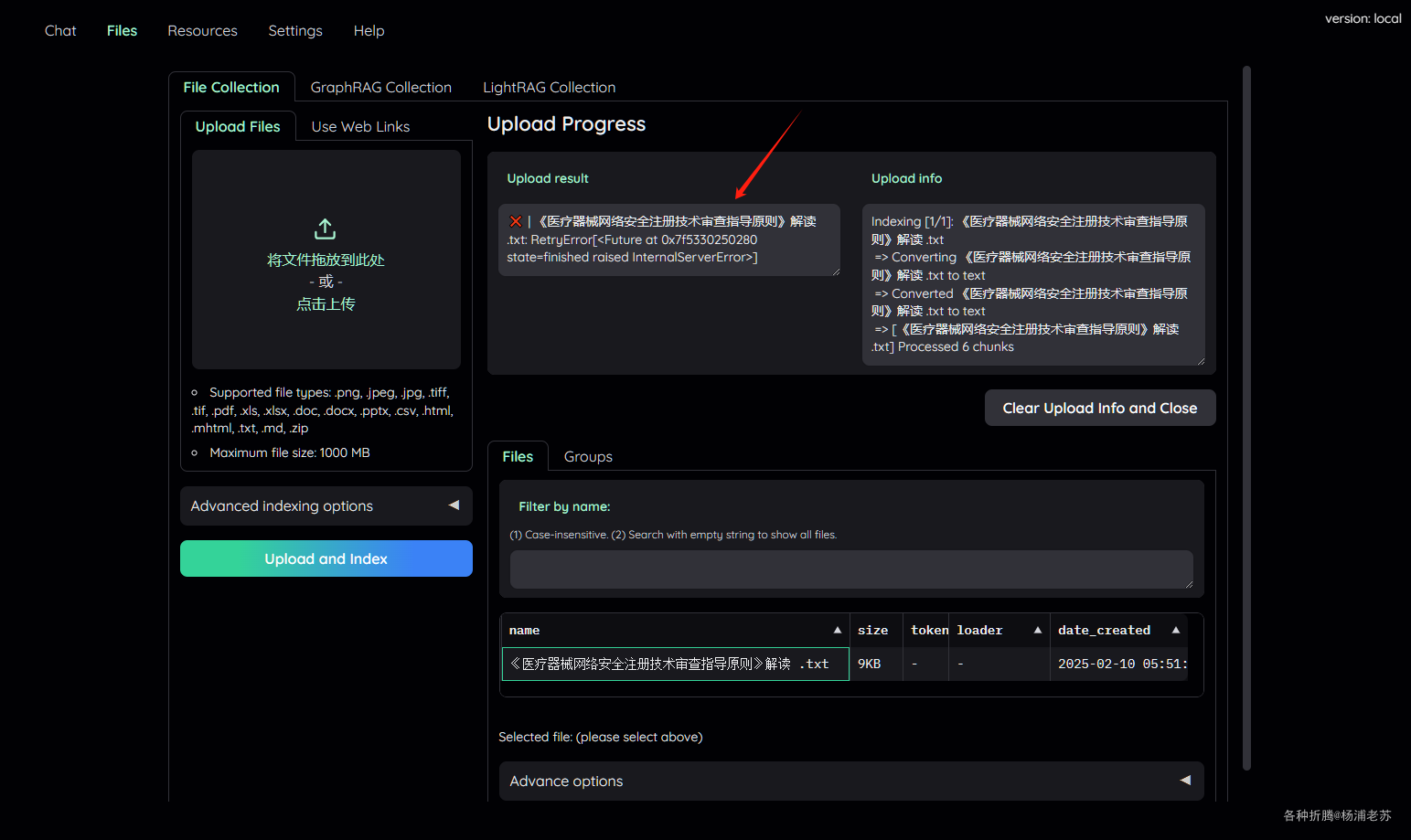
上传文件
点 Files 进入文件界面,上传一个文件,点 Upload and Index
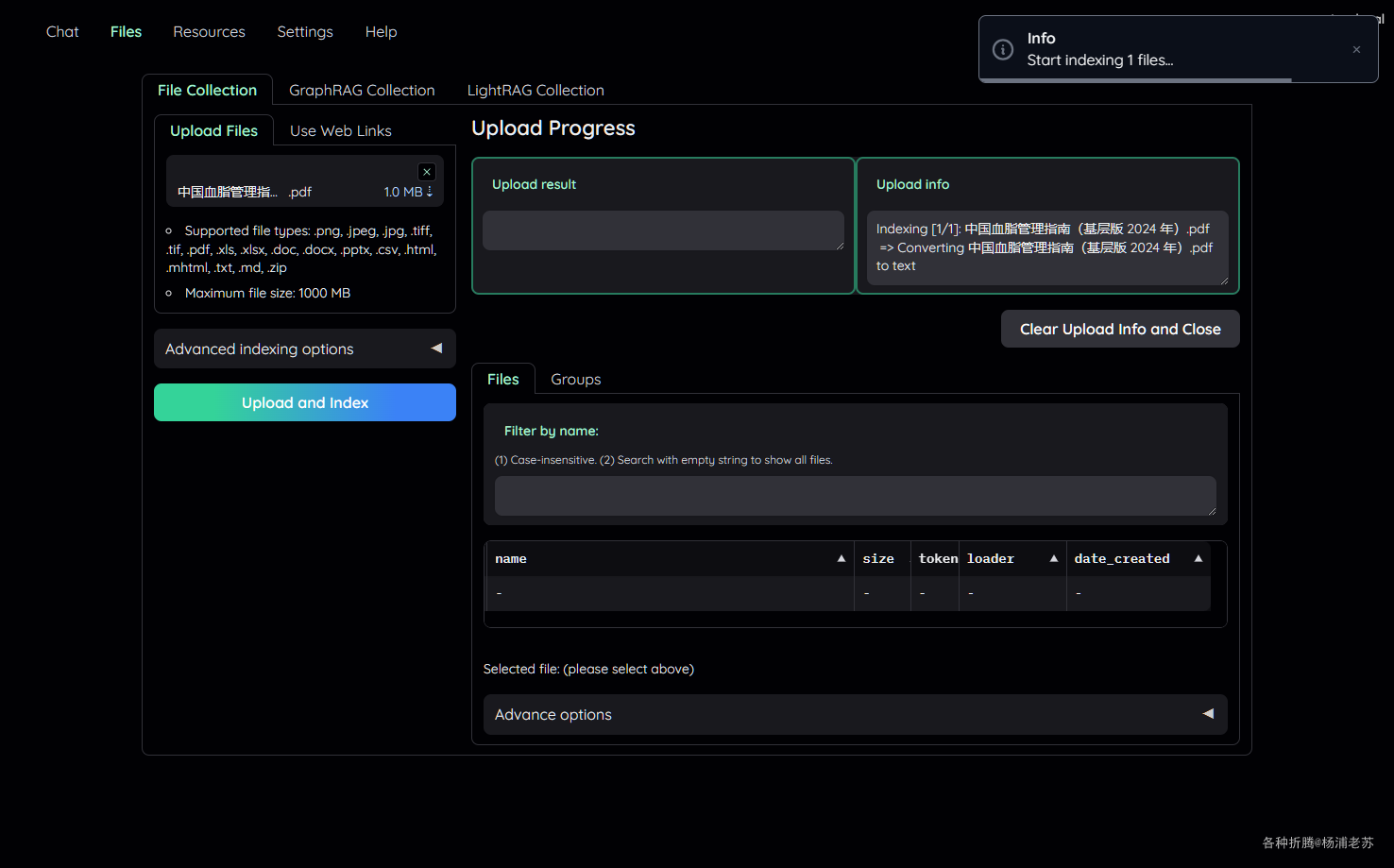
等待文件索引成功,时间取决于文件大小
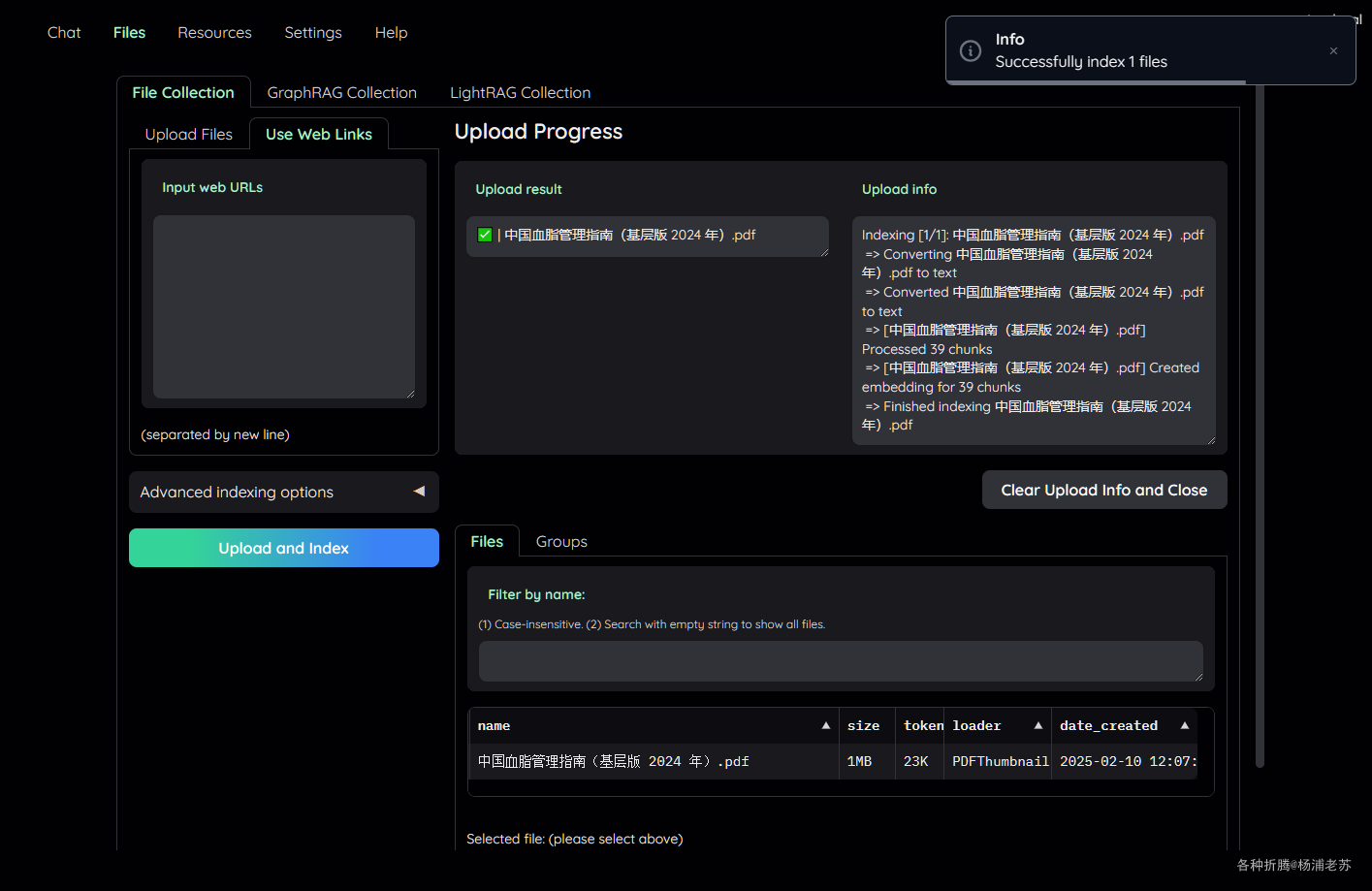
也可以在聊天界面快速上传
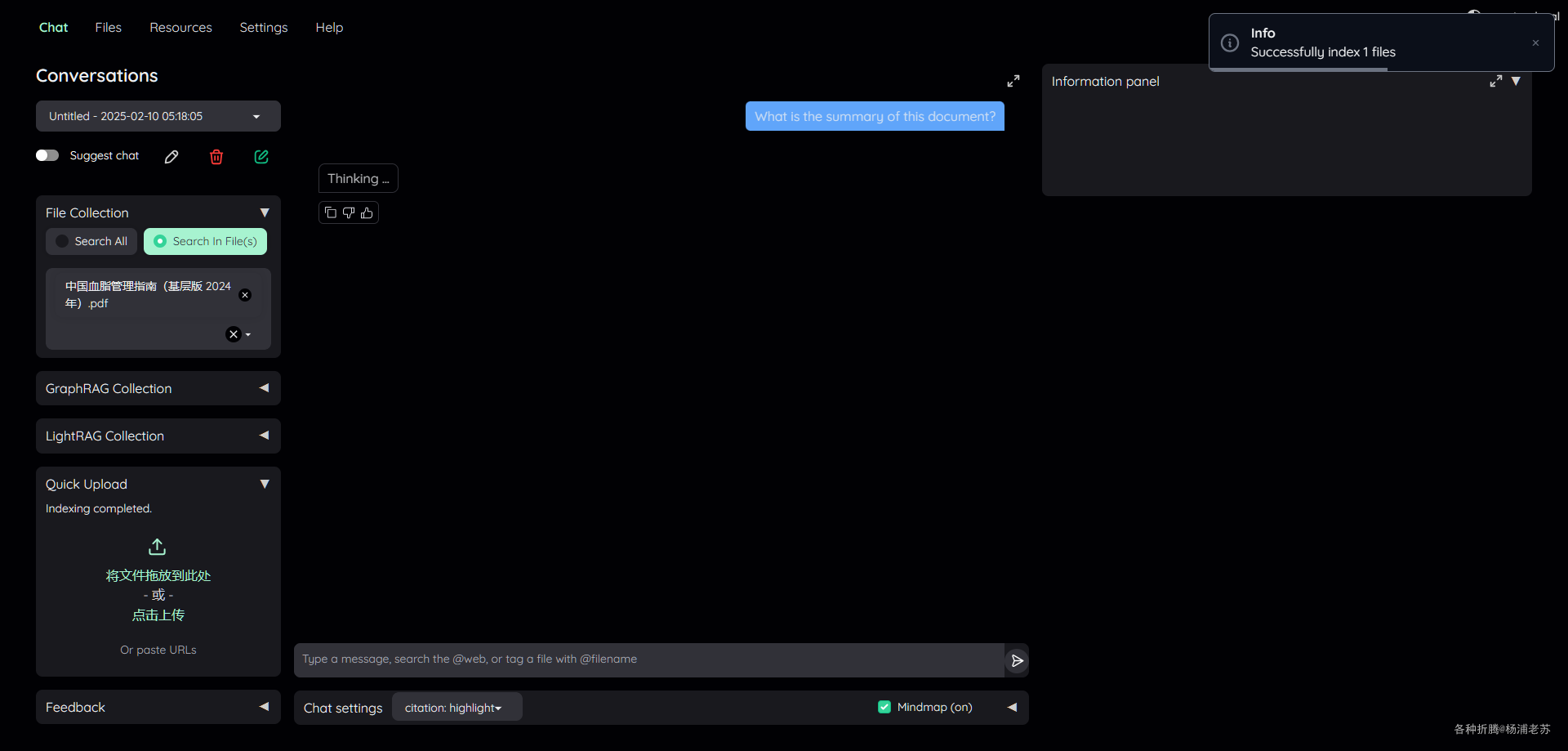
索引创建成功后,就可以跟文件开始聊天了
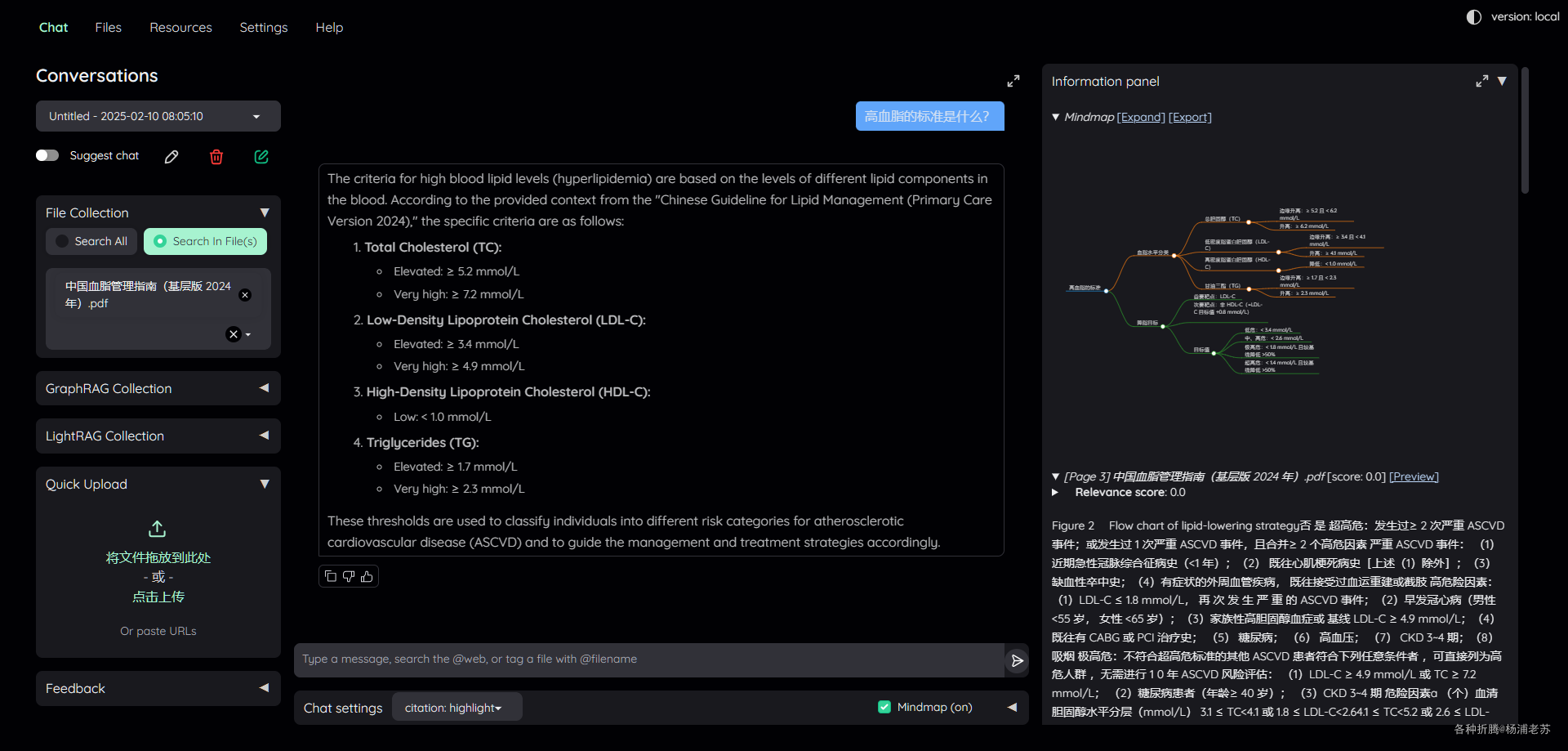
默认回答是 英文 的,改成中文后,再次提问
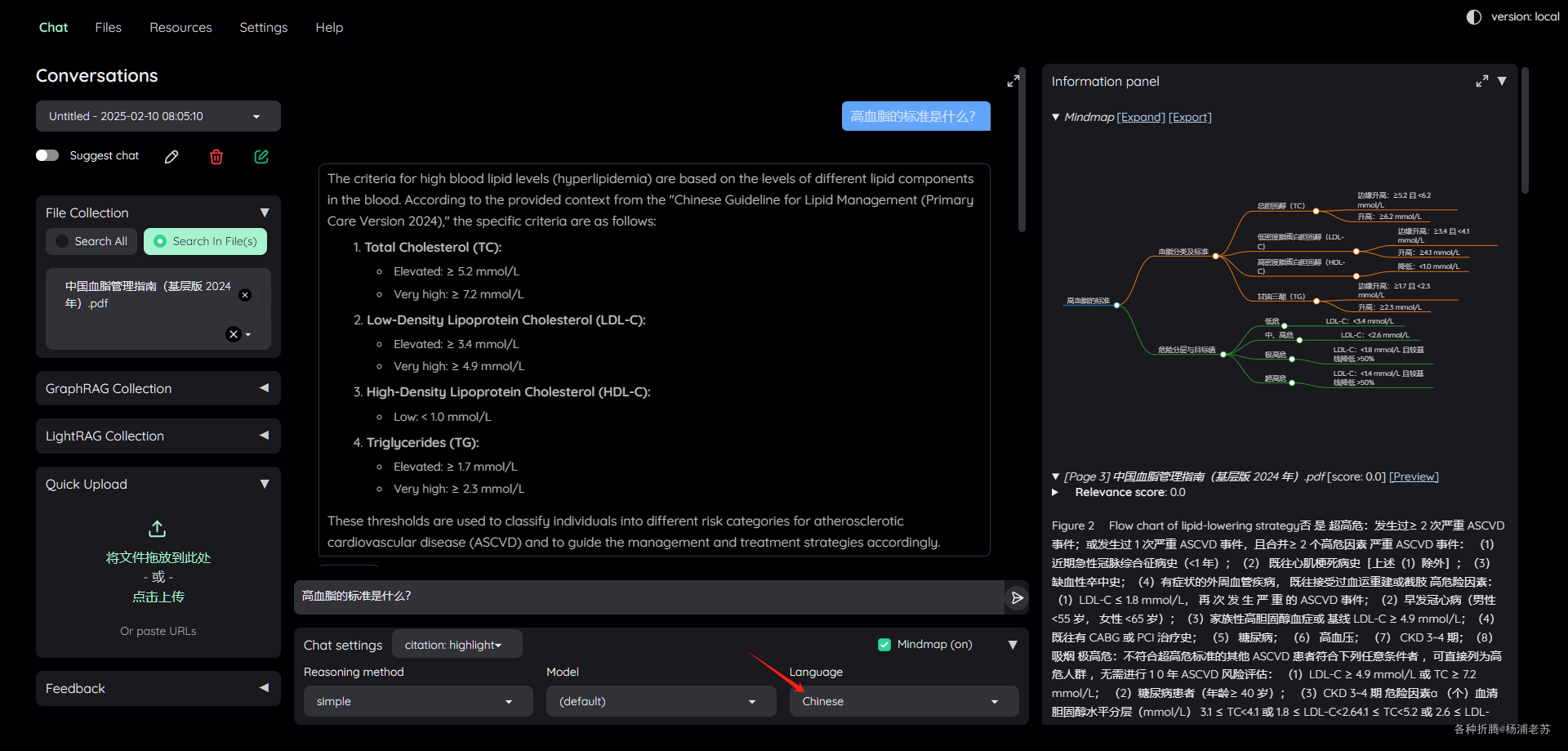
现在的回答是中文了
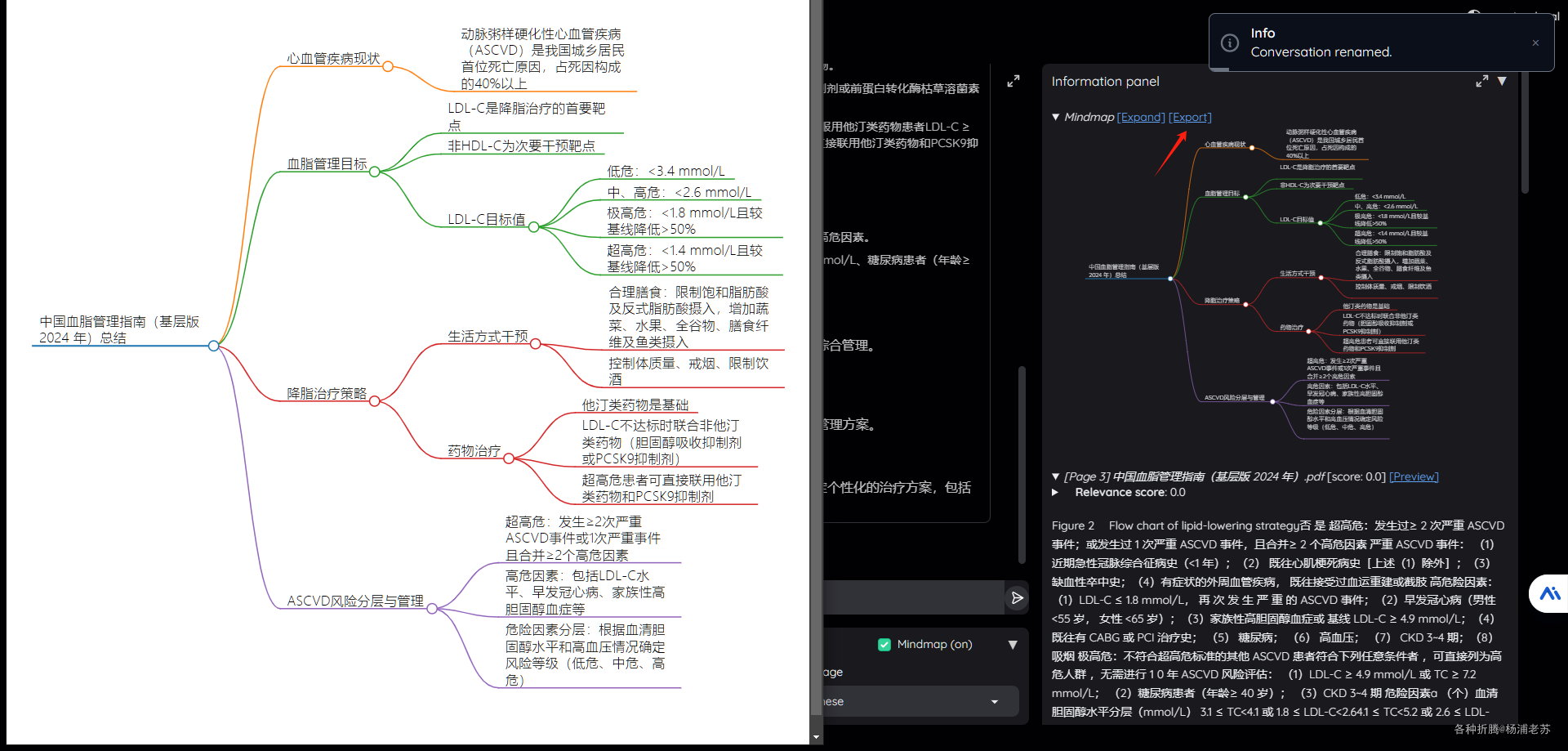
脑图上点 export 会弹出新窗口
参考文档
Cinnamon/kotaemon: An open-source RAG-based tool for chatting with your documents.
地址:https://github.com/Cinnamon/kotaemonQuick Start - kotaemon Docs
地址:https://cinnamon.github.io/kotaemon/